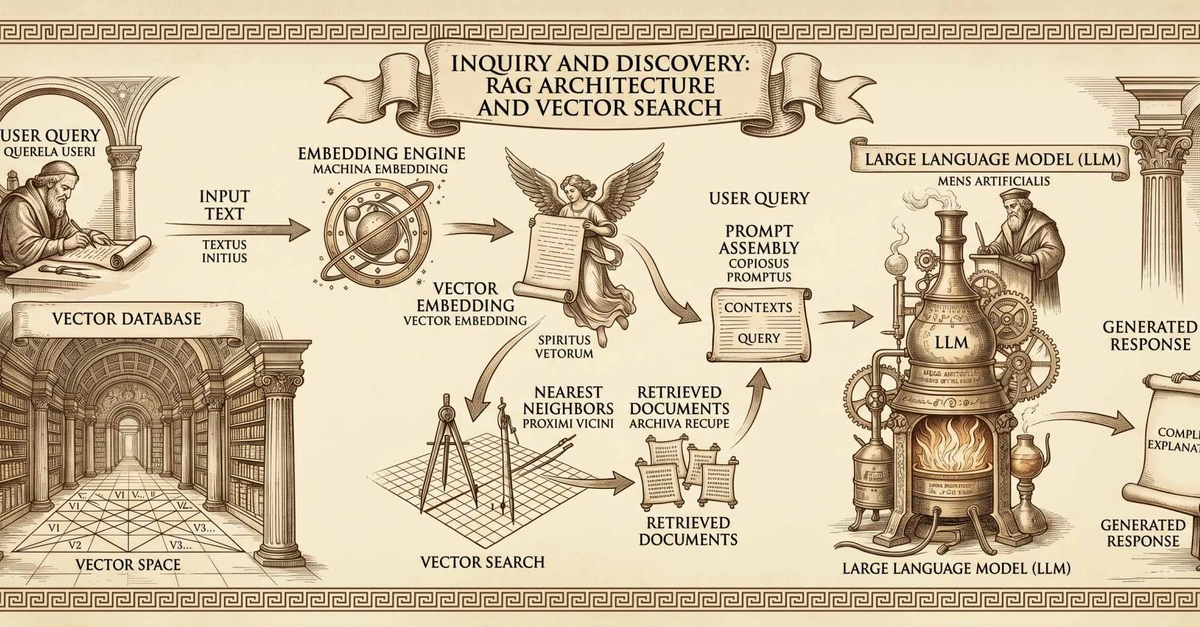
Your users don't search the way databases expect them to. They might type "warm zip-up jacket" when your catalog says "thermal fleece pullover," or ask for "the dude who teaches rock" when the answer is "School of Rock." Traditional keyword search returns zero results when terms don't overlap—and suddenly your app looks broken.Vector search closes that gap by matching meaning instead of exact words. It's a retrieval layer powering retrieval-augmented generation (RAG), recommendation engines, semantic caching, and agentic AI systems.This article covers what vector search is, how it accelerates LLM apps, where it cuts costs, why performance at scale matters, and how unified infrastructure simplifies operations.What vector search is & why it mattersVector search finds results by meaning, not exact keywords, making it a foundation for modern AI apps that need to understand user intent at scale. It works by converting data into mathematical representations called embeddings, then retrieving the most similar items using fast approximation algorithms.How embeddings represent meaningVector embeddings are dense arrays of floating-point numbers that represent data like text, images, and audio in a high-dimensional space. The key property: proximity in that space maps semantic similarity. Two sentences about the weather land close together; a sentence about driving lands far away. Transformer-based models generate these embeddings so that similar content clusters naturally.How retrieval works at query timeDocuments are embedded at index time. At query time, the incoming query is embedded, then the closest stored vectors are found using distance metrics like cosine similarity or Euclidean distance. The standard retrieval pattern is Top-K: return the K most semantically similar results.Scaling with approximate nearest neighbor algorithmsBrute-force exact nearest-neighbor search is O(dn): cost grows with both the number of vectors and their dimensionality. That doesn't scale.Approximate nearest neighbor (ANN) algorithms trade a small amount of accuracy for dramatically faster retrieval, and you'll typically choose between two approaches. Hierarchical Navigable Small World (HNSW) creates a multi-layer graph that typically scales logarithmically for search. The trade-off: HNSW uses additional memory to store graph links, increasing storage requirements in exchange for faster, higher-recall search. Alternatively, Inverted File with Product Quantization (IVF-PQ) reduces memory usage by compressing vectors into compact codes, trading some accuracy for much lower storage requirements.Build fast, accurate AI apps that scaleGet started with Redis for real-time AI context and retrieval.The limits of pure vector searchPure vector search isn't a silver bullet. It hits support limits for exact phrase matching, boolean logic, proximity search, and advanced linguistic processing. That's why hybrid search, which combines vector and keyword retrieval, is increasingly the standard in production systems.How vector search accelerates LLM appsThat retrieval layer matters even more once you plug it into LLM apps. Vector search is a retrieval backbone for several patterns that can make LLM apps faster, more accurate, and less expensive to run.Retrieval-augmented generation (RAG): grounding LLMs in real dataRAG helps keep LLMs accurate by feeding them your data at query time, instead of relying on whatever the model memorized during training. This pattern has become a standard way to build LLM apps that answer questions about proprietary or real-time information.At query time, the app embeds the user's query, retrieves the most relevant chunks from the vector index, and passes those results to the LLM as context.The impact shows up in benchmarks. One multi-agent RAG system reported hallucination rates dropping from 15% to 1.45% compared to LLM-only baselines. An ablation study also found that removing vector search caused noticeable multi-hop performance drops, underscoring the role of retrieval in answering natural-language questions. That said, retrieval isn't a complete fix on its own. Models can still generate unsupported content even when given the correct context.Semantic caching: skipping redundant inferenceSemantic caching can reduce LLM costs by recognizing when two queries mean the same thing, even if they're worded differently. Instead of paying for a fresh inference call every time, your app serves a cached response for repeat intent.It stores prior query-response pairs as vector embeddings and returns cached responses for semantically equivalent queries. The cache-hit potential is real: in one analysis of ChatGPT conversations, about 31% of user queries were similar to previous ones from the same user. Redis LangCache is a managed semantic caching service for LLM apps. In high-repetition workloads, it reported up to ~73% lower LLM inference costs without code changes.Semantic routing & agent memorySemantic routing uses vector similarity to pick which retrieval source or pipeline to query before any document lookup runs. One federated-search routing approach reported up to a 52.50% latency reduction across three benchmarks by skipping lookups against irrelevant sources.Agent memory does the same for conversation context: past interactions are stored as embeddings and the most relevant ones get retrieved at each inference step. In one benchmark on multi-turn, co-reference-heavy conversations, memory-augmented systems reported higher accuracy than systems without prior-context retrieval.Cost optimization beyond cachingCaching catches duplicate intent, but vector search also trims cost on the LLM calls that do go through.The first saving comes from better retrieval. Sending entire documents to an LLM costs more per call and can degrade output quality as the context window fills up. Vector retrieval sends only top-ranked passages, and combining it with structured metadata filtering tightens that further: one example reported improved Precision@5 from 58% to 87%, so fewer irrelevant chunks landed in the prompt.The second comes from where embedding work runs. In most RAG pipelines, document embeddings are computed once at index time, not on every query. The real-time path runs vector retrieval only, with no embedding cost per request.Search meaning, not just keywordsUse Redis vector search to deliver smarter results instantly.Performance advantages at scaleCost gains only matter if retrieval still feels fast under load, and that depends on more than algorithm choice. Some ANN methods reduce query complexity from linear to sub-linear (DiskANN, for example, reports logarithmic complexity at billion scale), but the algorithmic advantage shows up in practice only if the storage architecture behind the index can translate it into low retrieval latency.Why in-memory architecture mattersVector search algorithms like HNSW jump between many small pieces of data scattered across the index to find each query's nearest neighbors. When that data lives in RAM, each jump takes nanoseconds. When it lives on disk, each jump means a solid-state drive (SSD) read, which is orders of magnitude slower. Even DiskANN, optimized for disk, needs as few as 50 SSD reads per query to hit 90% recall on a billion-vector dataset.That gap matters for real-time apps. Recommendations, search-as-you-type, and live chat all need responses in well under a second. In-memory retrieval stays comfortably inside that envelope across most workloads; disk-based retrieval runs closer to the line as data and concurrency scale.Unified infrastructure reduces operational complexityEven fast vector search creates operational drag if it lives in its own silo. Running a separate vector database, cache, and operational store means more infrastructure to provision, sync, and monitor, with more ways for things to go wrong.The cost of running separate systemsSplitting search across systems multiplies the work. Teams often run a purpose-built vector database alongside a traditional search engine, each requiring independent infrastructure, configurations, and maintenance. Separate provisioning means separate on-call coverage and more integration points to fail.The synchronization problemThe problem gets worse when you split caching and operational data into the mix. Running a separate cache alongside a vector database and an operational store creates a three-way consistency challenge. Cache invalidation is one of the hardest caching problems, and when concurrent cache misses aren't coordinated, subsequent lookups can return different values.One platform for vectors, cache, & operational dataA unified platform helps reduce these failure modes. Redis supports vector search alongside caching and data structures, so cached responses, session data, and application state can live in one place, with one monitoring setup, one set of access controls, and one operational surface to manage.Use cases where vector search delivers valueOnce vector search and the rest of the data stack live in one place, it gets easier to put into production. Vector search already powers production systems across e-commerce, financial services, healthcare, and conversational AI. The common thread: each domain depends on matching meaning, not exact strings, and each one benefits from sub-millisecond retrieval at scale.Here are four of the highest-impact apps:E-commerce product discovery. When shoppers search "warm zip-up jacket" but your catalog says "thermal fleece pullover," keyword search returns nothing. Vector embeddings map both phrases to nearby points in semantic space, so the right product surfaces even when the words don't match. The same approach powers "more like this" recommendations and visual search across product images.Fraud detection. Rule-based systems struggle against novel fraud patterns because attackers change tactics faster than rules can be written. Vector embeddings of transaction sequences capture structural similarity, so new fraud types get flagged when they land close to historical fraud archetypes in embedding space. A recent literature review of 57 deep-learning studies across credit card transactions, insurance claims, and financial audits highlights transformer-based models among the effective approaches evaluated.Healthcare decision support. Clinical knowledge is vast, unstructured, and constantly evolving, so keyword lookups miss relevant guidance when terminology varies between sources. Vector search retrieves semantically similar literature and guidelines so clinicians can find evidence even when phrasing differs. One PubMed retrieval study demonstrated semantic retrieval at scale, and agentic guideline retrieval measured up to +0.2308 sensitivity for rheumatoid arthritis clinical guidelines.Conversational AI & chatbots. RAG chatbots use vector search to ground responses in domain-specific knowledge such as product docs, support tickets, and internal wikis, so the model answers from your data instead of guessing. When retrieval misses, even the best model hallucinates around the gap.Across all four, the pattern is the same: encode meaning as vectors, retrieve by similarity, act on the results in real time.Now see how this runs in RedisPower AI apps with real-time context, vector search, and caching.Redis as the real-time AI data layerVector search has matured from a niche AI experiment into a core layer of the modern app stack. It powers RAG, semantic caching, and agent memory in LLM apps, helps reduce inference costs by trimming the context window and skipping duplicate calls, and supports real-time performance at scale when backed by in-memory architecture, especially when vectors, cache, and operational data share one platform.Redis combines vector search with sub-millisecond performance for many core operations in a single real-time data platform, letting you add semantic search without introducing a separate vector database. If you're already using Redis for caching or session management, your embeddings can live alongside the data structures your app already depends on. With AI stack integrations across major frameworks and clouds, Redis fits into the AI stack you're likely already building.Try Redis free to see how vector search works with your data, or talk to the team about your AI infrastructure.
Advantages of Building a Vector Search Solution
Vector search matches meaning, not just words. Learn how it powers RAG, cuts LLM costs, and scales with in-memory architecture using Redis.
1,777 words~8 min read