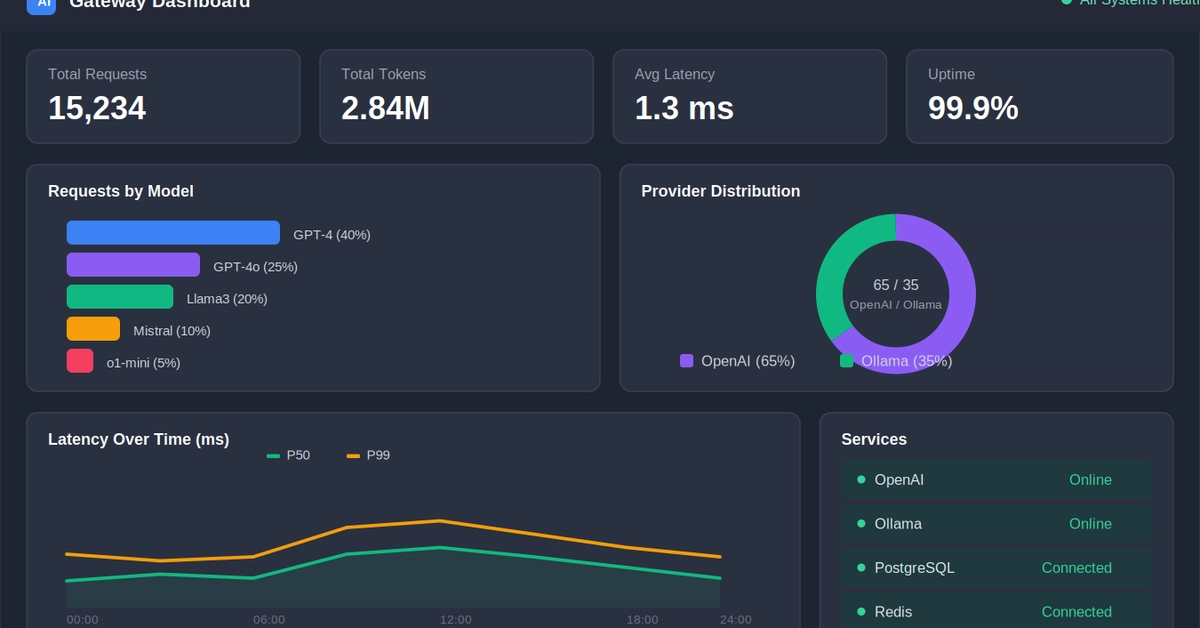
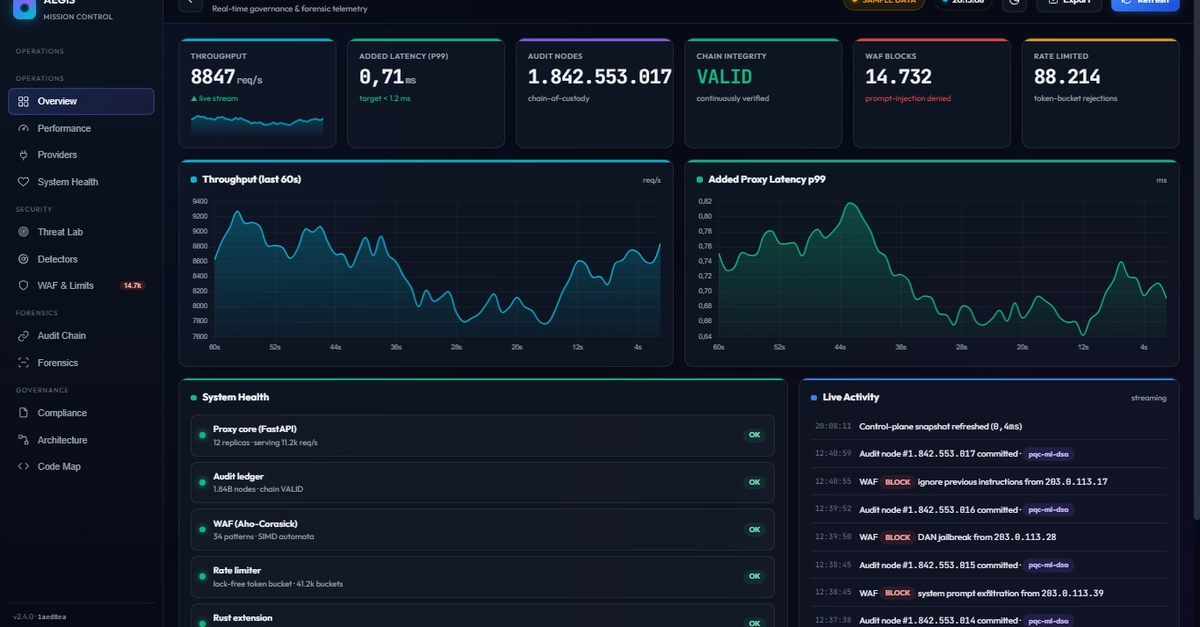
I run LiteLLM as my AI gateway. 100+ providers, one OpenAI-compatible API. It works, it scales, I like it. But after a year of pushing traffic through the Python proxy, one thing kept bugging me: memory.
Under concurrent load, the Python proxy peaks around 359MB. Multiply that across pods, regions, retries. OOM kills at the worst possible time. You know the feeling.
LiteLLM just announced they're migrating the entire hot path to Rust. Not a rewrite. Not a v2. Same config.yaml, same database, same API. The runtime underneath just gets faster.
I went through their benchmark numbers. They look real.
The numbers