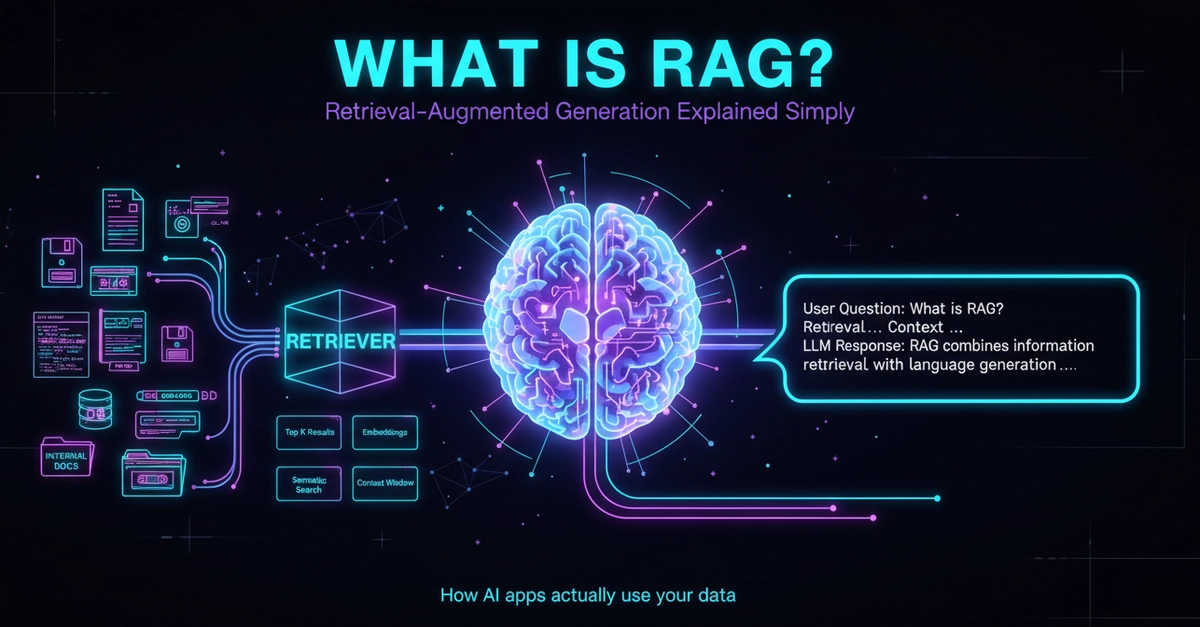
I had used LangChain's RAG chain in production for six months. I could not have told you, off the top of my head, what chunk_overlap did, or why cosine similarity is the right distance metric, or how nomic-embed-text actually turns a sentence into a vector. The high-level library abstracted all of it away.
So one weekend I deleted the LangChain dependency and wrote a RAG pipeline from scratch in ~500 lines of plain Python. No framework, no magic. pypdf for text extraction. A 60-line chunker. ChromaDB for the vector store. Ollama for embeddings and the LLM. The whole thing is on GitHub — every module is under 200 lines, every test is deterministic, and you can read the whole thing in one sitting.
This is the build log. Not a tutorial — the build log, with the parts that surprised me and the parts I got wrong the first time.
Why bother
The honest reason: I was using LangChain's RetrievalQA chain and getting answers I didn't trust. Sometimes the model would say "according to the document" when the document didn't say that. Sometimes the citations were wrong. I had no way to know if the chunker was dropping important context, or if the cosine similarity was picking the wrong neighbors, or if the prompt was actually constraining the model. The library was a black box.