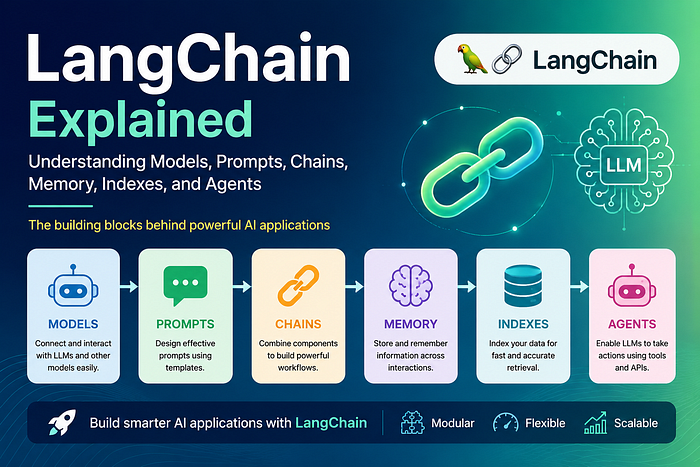
When building prototypes with Generative AI, velocity is everything. Developers want to stitch together prompts, text splitters, vector stores, and models as quickly as possible. This need for speed catalyzed the explosive rise of orchestration frameworks like LangChain.
However, as a backend systems engineer with over a decade of experience maintaining production microservices, my perspective changes when moving code from prototype to a high-volume enterprise environment. In production engineering, we must weigh every external package dependency against its architectural debt. We look closely at abstraction layers, debugging visibility, maintenance overhead, and breaking changes.
This article provides an objective, side-by-side architectural comparison of building GenAI data pipelines using two distinct paradigms: Pure Native Python vs. LangChain Expression Language (LCEL).
1. The Core Dilemma: The Cost of Abstraction
In traditional backend engineering, we are deeply familiar with the trade-offs of heavy abstractions. Consider Object-Relational Mappers (ORMs). An ORM makes simple CRUD operations incredibly easy. However, when you need to optimize a complex SQL join or debug a hidden memory leak, that abstraction can become a barrier, obscuring the raw operations happening underneath.