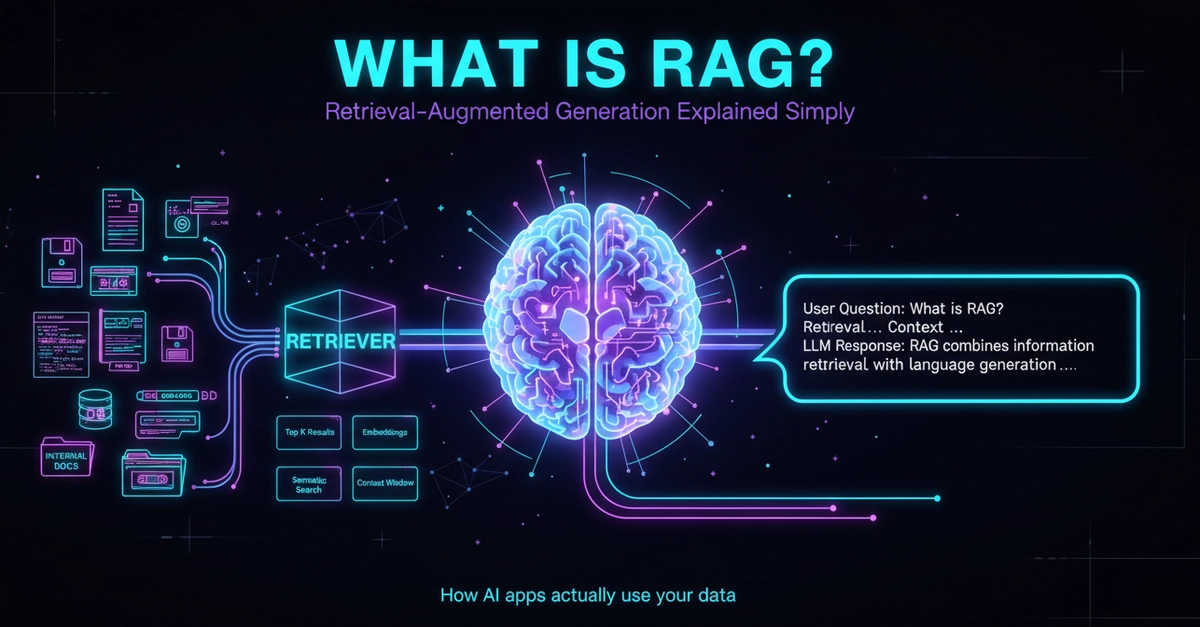
Your vector database is returning relevant chunks. Your embedding model scores 0.89 on retrieval benchmarks. Your PM calls it "AI-powered search." But when a researcher asks "what are the methodological limitations of study X given our lab's prior work?", the system returns a paragraph about the weather in Tokyo.
This is the retrieval hallucination problem — and it's not a model failure. It's a retrieval architecture failure that no amount of LLM tuning fixes.
I found an approach that actually works in the wild: a Japanese research team's knowledge graph RAG system that achieved 90% accuracy improvement on scientific paper comprehension tasks. The post (on Qiita, Japan's largest developer community) documents their implementation in detail. But here's what caught my eye — their solution isn't a better embedding model. It's a fundamentally different retrieval architecture that most Western teams haven't considered.
The Semantic Gap Nobody Acknowledges
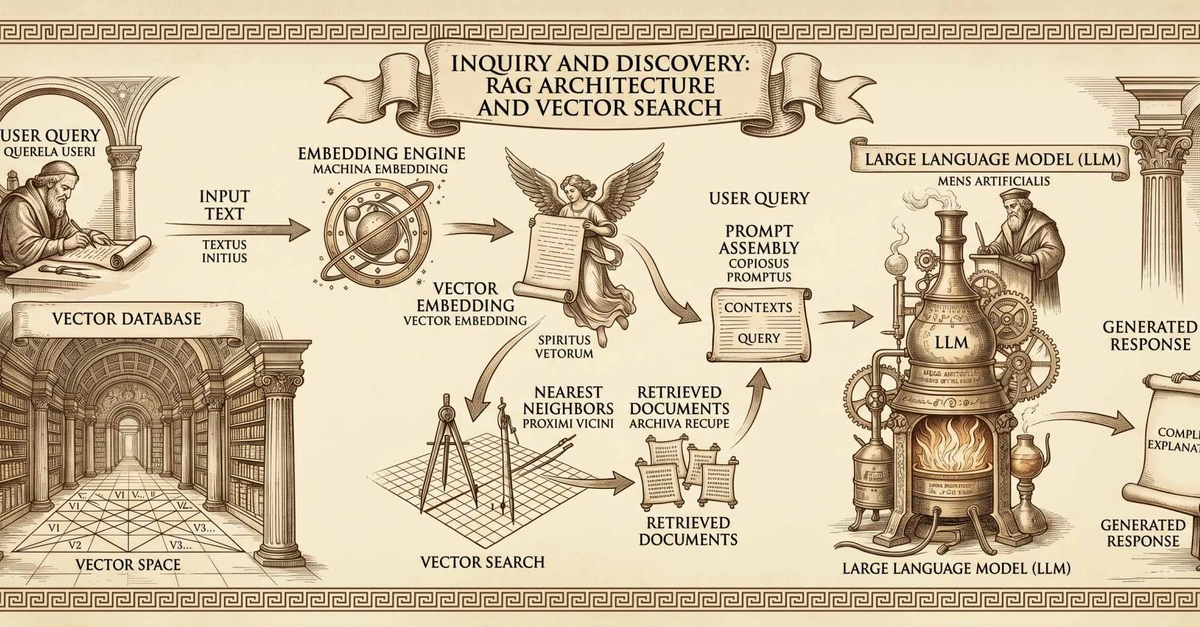
Standard RAG works like this: chunk documents, embed chunks, store in vector DB, retrieve based on cosine similarity. The problem? Semantic similarity ≠ relevance. A chunk about "protein folding methods" might be topically similar to your query about "CRISPR editing limitations," but if the chunk mentions both in a literature review, it's not answering your question.