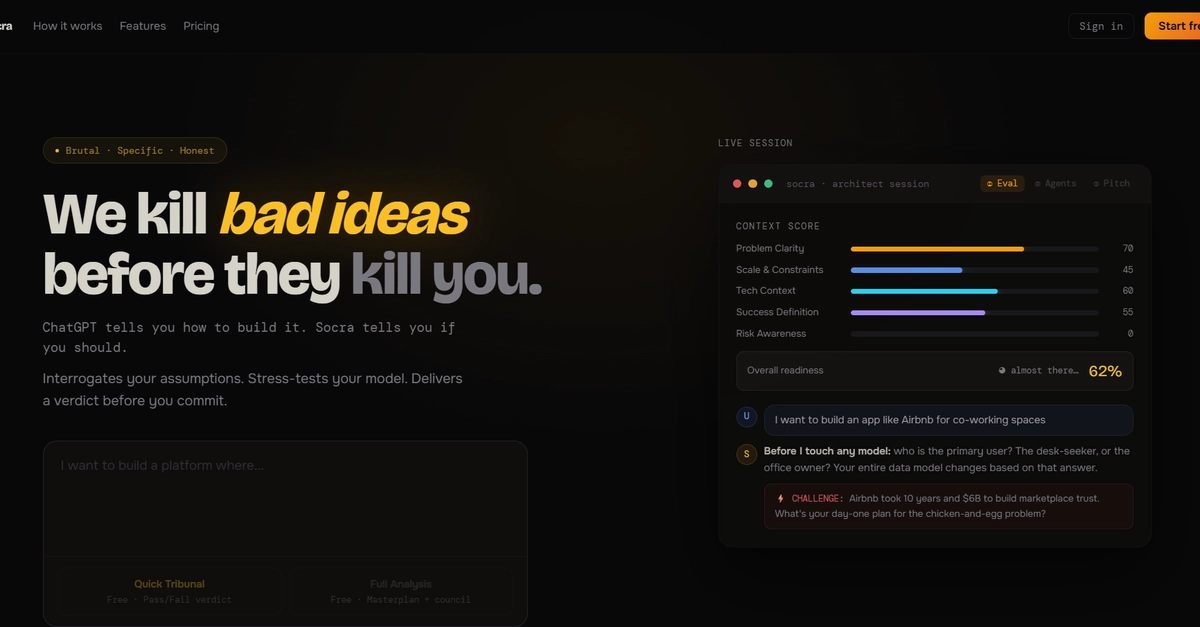
TL;DR: We run an LLM-backed build-failure summariser at Buildkite. To stop a provider wobble from breaking it mid-deploy, I ran a game day that fault-injected OpenAI with 429s and 500s and watched whether Bifrost's fallback config actually rerouted. It did, but only after I fixed two things I'd set up wrong.
We've got a small service that reads failed CI jobs and writes a one-paragraph summary into the build annotation, so engineers don't have to scroll 4,000 lines of test log to find the one assertion that broke. It calls an LLM. Handy when it works. Embarrassing when it doesn't, because a broken annotation makes people distrust every annotation.
The problem is the thing it depends on isn't ours. OpenAI rate-limits, has the occasional 5xx spell, and we don't get a heads-up. "Never had an outage" usually means you never tested the failure path. So I tested it.
Why a gateway at all
I didn't want fallback logic smeared across our service code. Retry-with-jitter, secondary provider, key rotation, all of that wants to live in one place with metrics attached. We put Bifrost in front, an OpenAI-compatible gateway, so our service keeps talking the same /v1/chat/completions it always did and the routing decisions move to config.