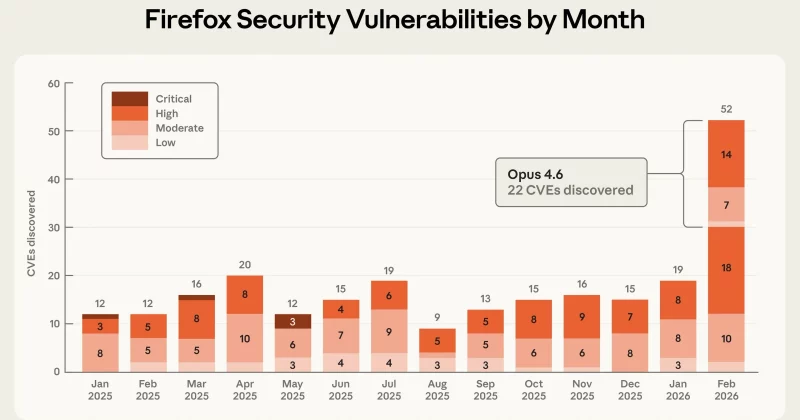
2026-06-1817 min readA few weeks ago, we published our initial findings from Project Glasswing, looking at what happens when you point frontier security models at an enterprise codebase. We also explored how our defensive structures adapt to protect our infrastructure and customers from threats posed by frontier AI. Since then, the AI ecosystem has continued to shift rapidly — developers who've built tightly around a single model have already experienced what happens when that model is no longer available or gets superseded by a more capable one. These market shifts only reinforce our core thesis: no matter which underlying model is leading the pack on any given day, the future of agentic workflows will not be found in standalone models, prompts, or single-agent sessions. Moving from a localized security "skill" to a continuous, fleet-wide scanning pipeline requires an architecture where models are treated as interchangeable components. Relying on a single model inherently limits defensive coverage, as the same system will tend to look at code paths through the exact same lens. To counter this, models should be frequently interchanged and cross-tested. By varying the models across the pipeline — such as using one model for initial discovery and an entirely different one for validation — we can ensure that vulnerabilities are cross-checked by distinct sets of logic. Furthermore, a true enterprise-scale harness must look beyond isolated repositories to trace vulnerabilities across cross-repo dependencies, ultimately filtering thousands of raw candidates down to a trusted, triaged queue of actionable fixes. This post serves as a practical look at how to build that model-agnostic layer, focusing on how we manage state controls, eliminate false positives, and coordinate end-to-end triage at scale.
Build your own vulnerability harness
We break down the technical architecture behind our multi-stage vulnerability discovery harness and automated triage loop. Learn how we manage state controls, squash false positives through adversarial review, and route around LLM context limits.
4,900 words~22 min read