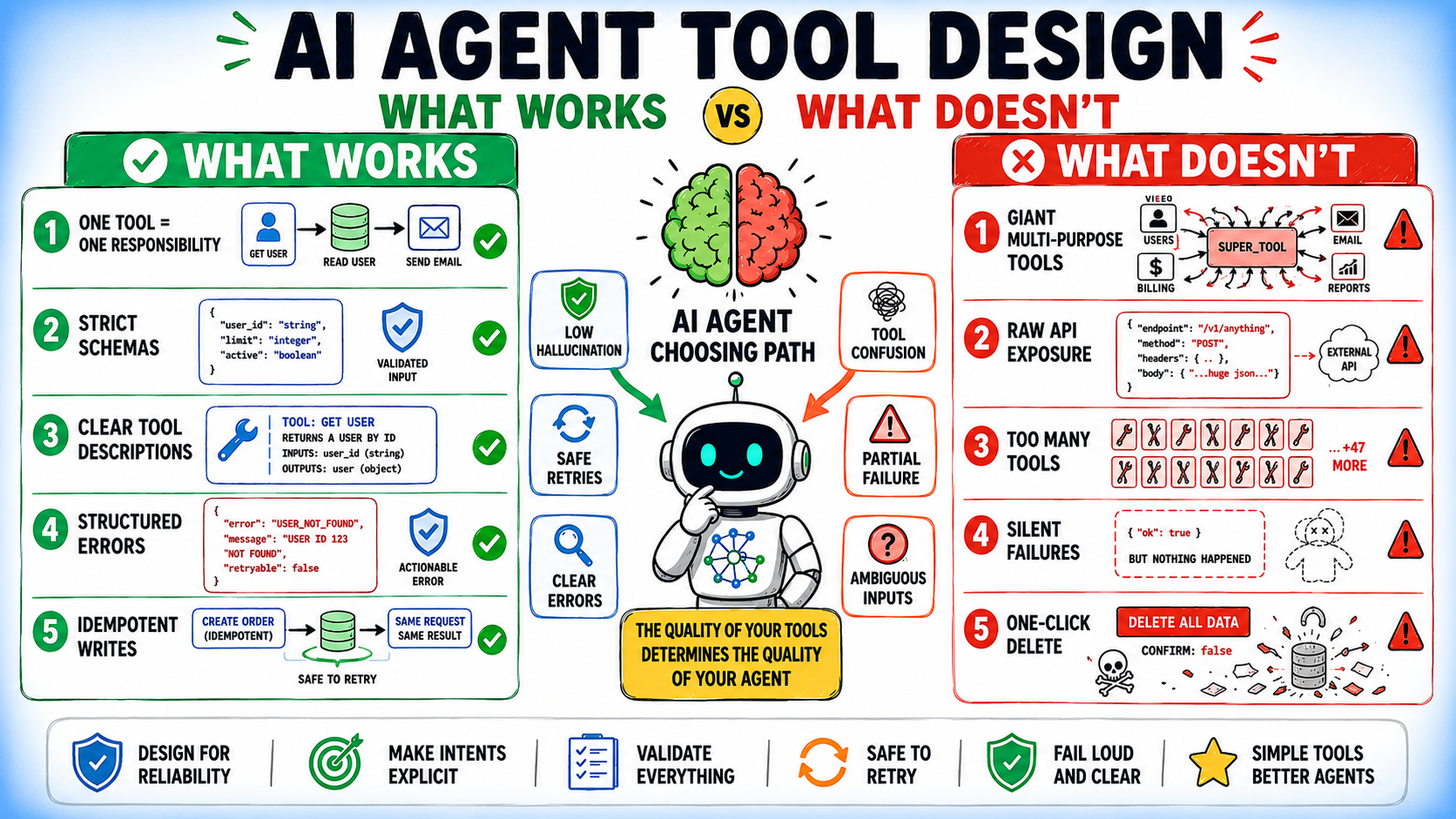
A few months into building AI agents for client projects, we hit a pattern that should sound familiar to anyone shipping this technology beyond the demo stage: the agent worked beautifully in front of stakeholders, then quietly fell apart the moment real users got their hands on it.
Not catastrophically. That would've been easier to catch.
A tool call would be made with a slightly malformed argument and get stuck in a retry loop. A multi-step task would drift away from its original objective halfway through execution. An agent would confidently report success while accomplishing nothing useful at all.
Nothing crashed. Nobody got paged. The damage was a slow leak of trust.
That's the moment we stopped treating reliability as a property the model would eventually have enough of and started treating it as something we had to engineer for directly.