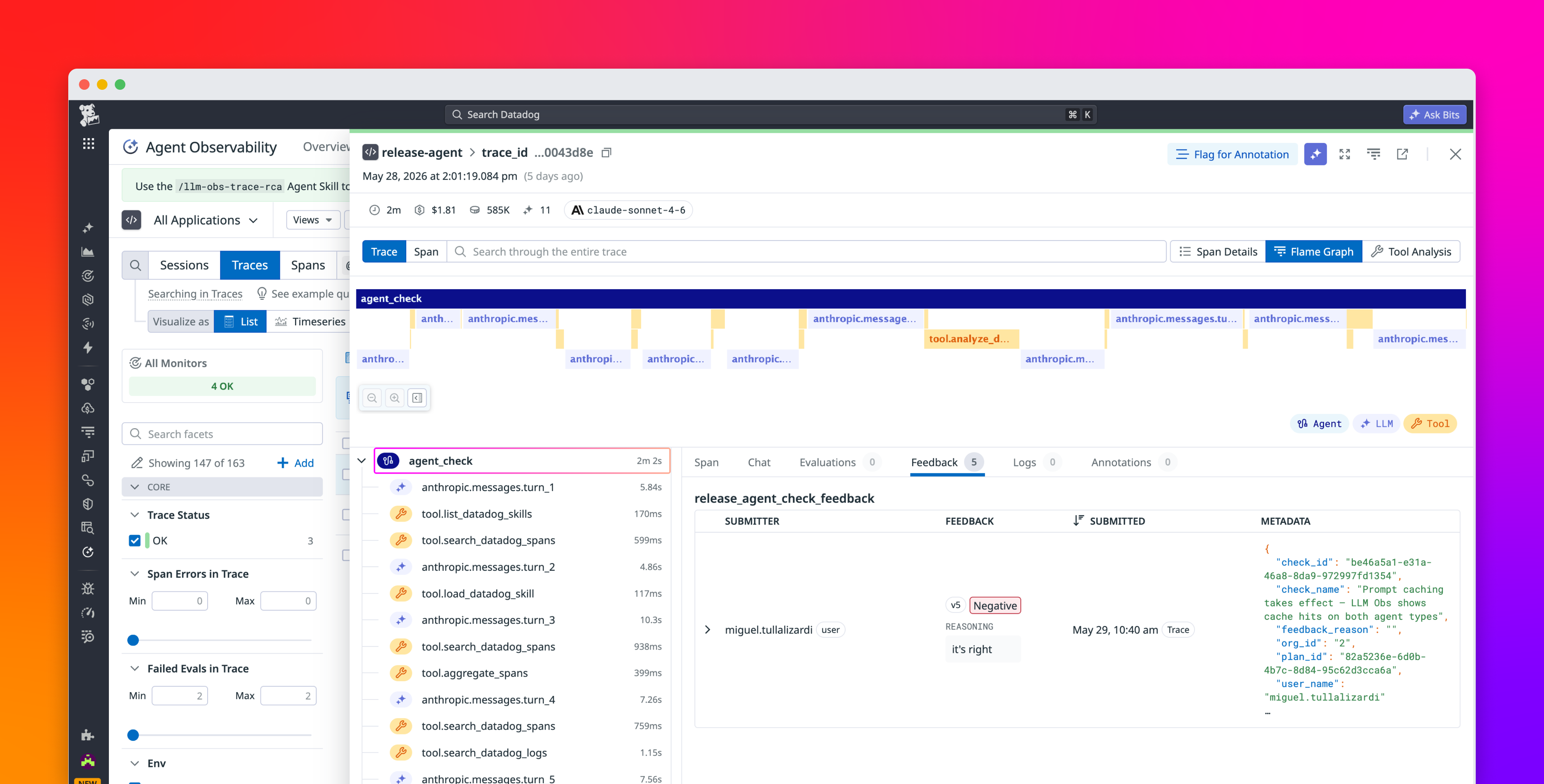
Part 5, the finale, of a series on building production AI on .NET. We've built the pieces — what evals are, error analysis, golden datasets, and a trustworthy judge. Now we make them earn their keep.
By now you can produce a defensible quality score for an AI feature. But a score you only look at is a vanity metric. The entire point of all that work is to make quality something your engineering process acts on automatically — the same way a failing unit test stops a bad commit. That means two homes for your evals: a gate before you ship, and monitoring after.
Home 1: CI — a safety net against regressions
Because TextStack's judge is a custom IEvaluator on Microsoft.Extensions.AI.Evaluation, an eval is just a dotnet test. The MEAI evaluator emits the rubric's axes plus an overall as numeric metrics, and a quality floor is expressed as a Pass/Fail interpretation on the overall:
// In the evaluator: the overall metric is interpreted Pass/Fail against a floor.