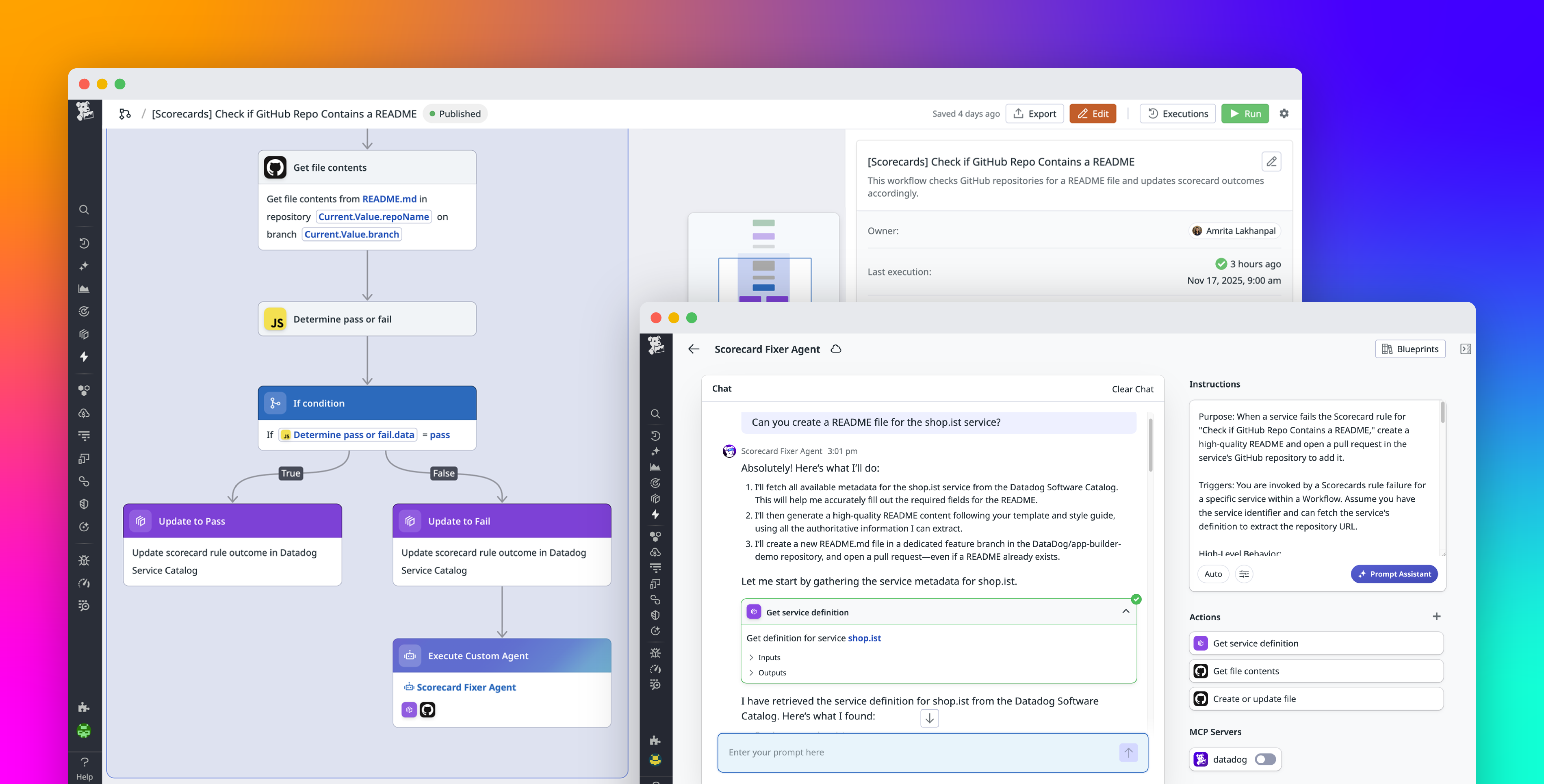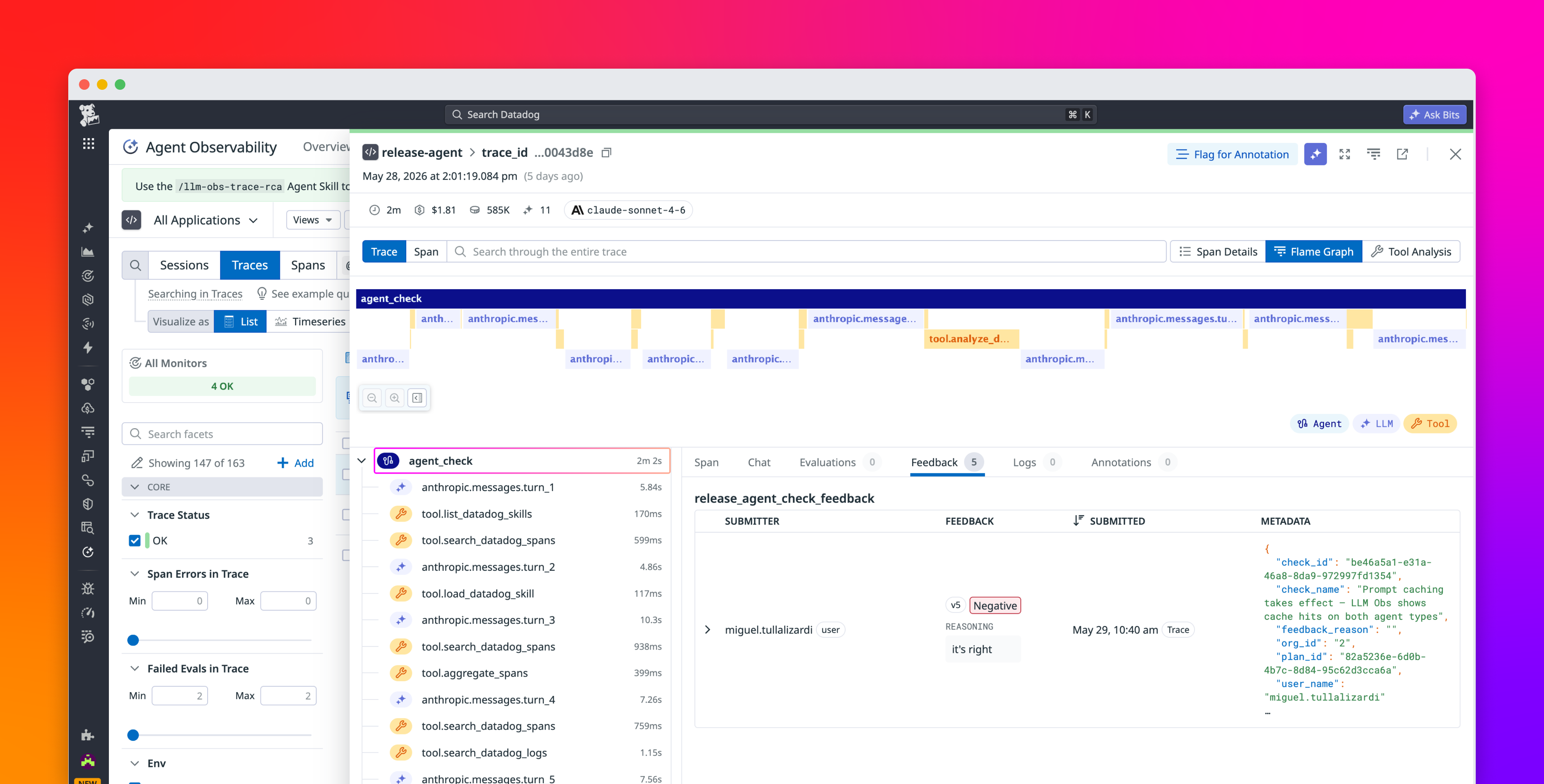
Coding agents such as Claude Code and Codex can handle much of the actual coding work involved in AI agent development, but they aren’t as well-equipped for other key tasks, such as setting up experiments and evaluations, analyzing errors and experiment results, and creating datasets. These activities require some level of human judgment, which makes the full AI agent development workflow hard to automate. While teams often develop and maintain custom scripts, skills, and runbooks to help them in these efforts, engineers still spend hours on manual work.
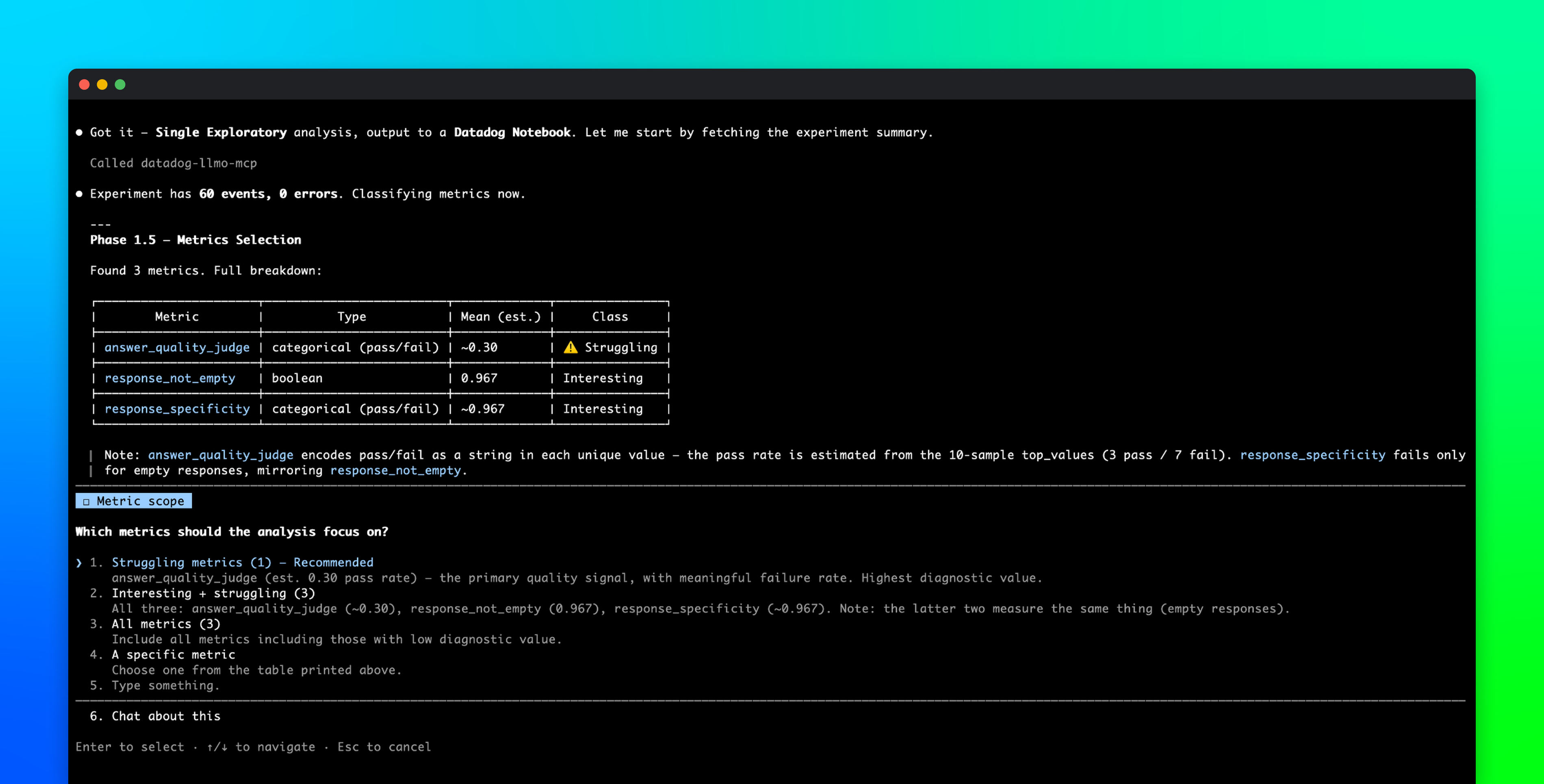
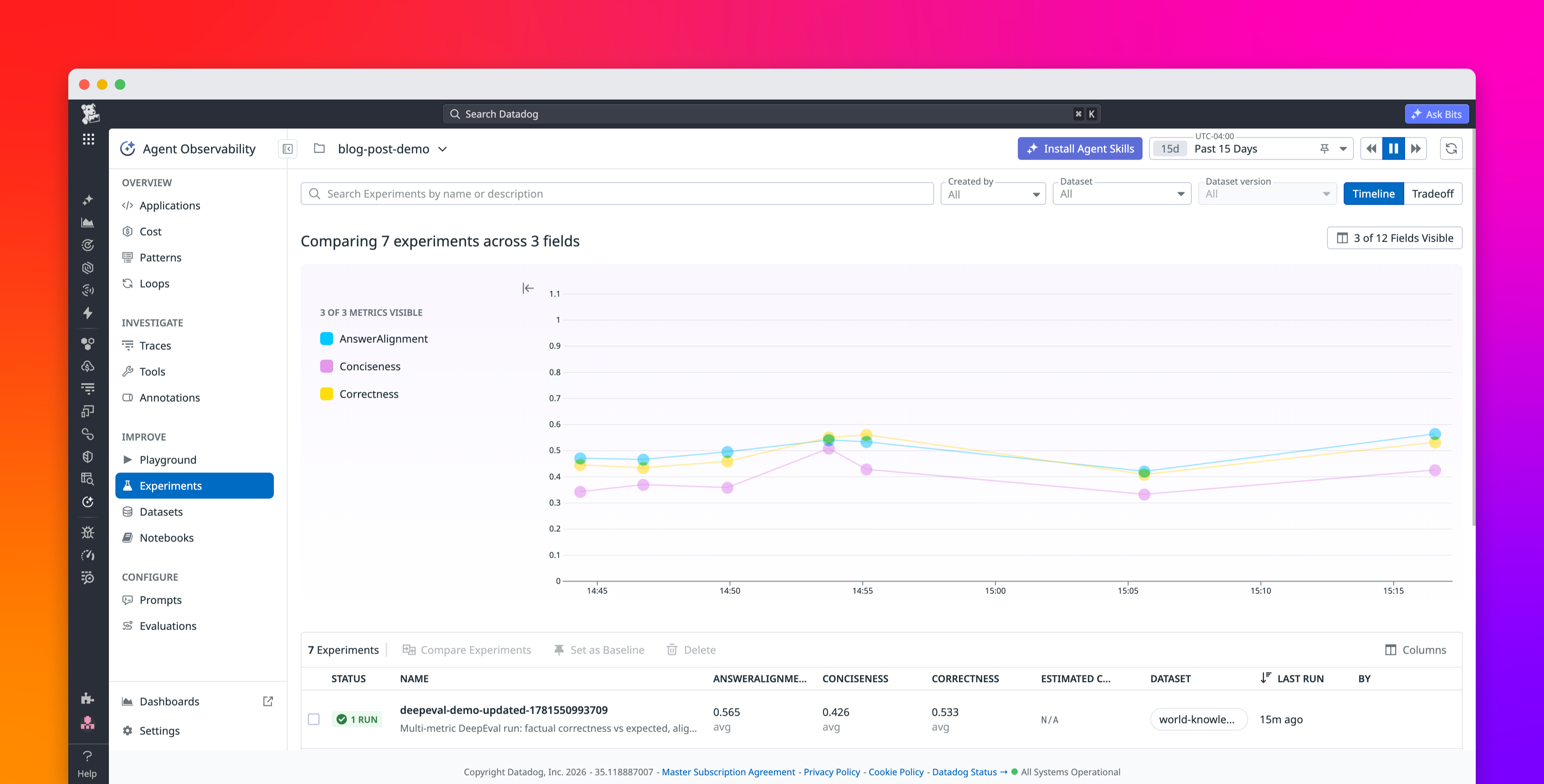
Bits Evals, available in Preview, is a set of agentic features that handles the repetitive parts of the agent development loop while keeping engineers in control of the decisions that matter. This helps your team move from a production failure to a validated fix and a shipped improvement in hours, not days. For example, instead of spending hours combing through traces to find examples to add to your offline evals, Bits Evals can do the first-pass error analysis for you. Based on online evals or customer input like thumbs up or down, it generates candidate dataset records and evaluators, while leaving the choice of which ones to pull into your experiments up to you.