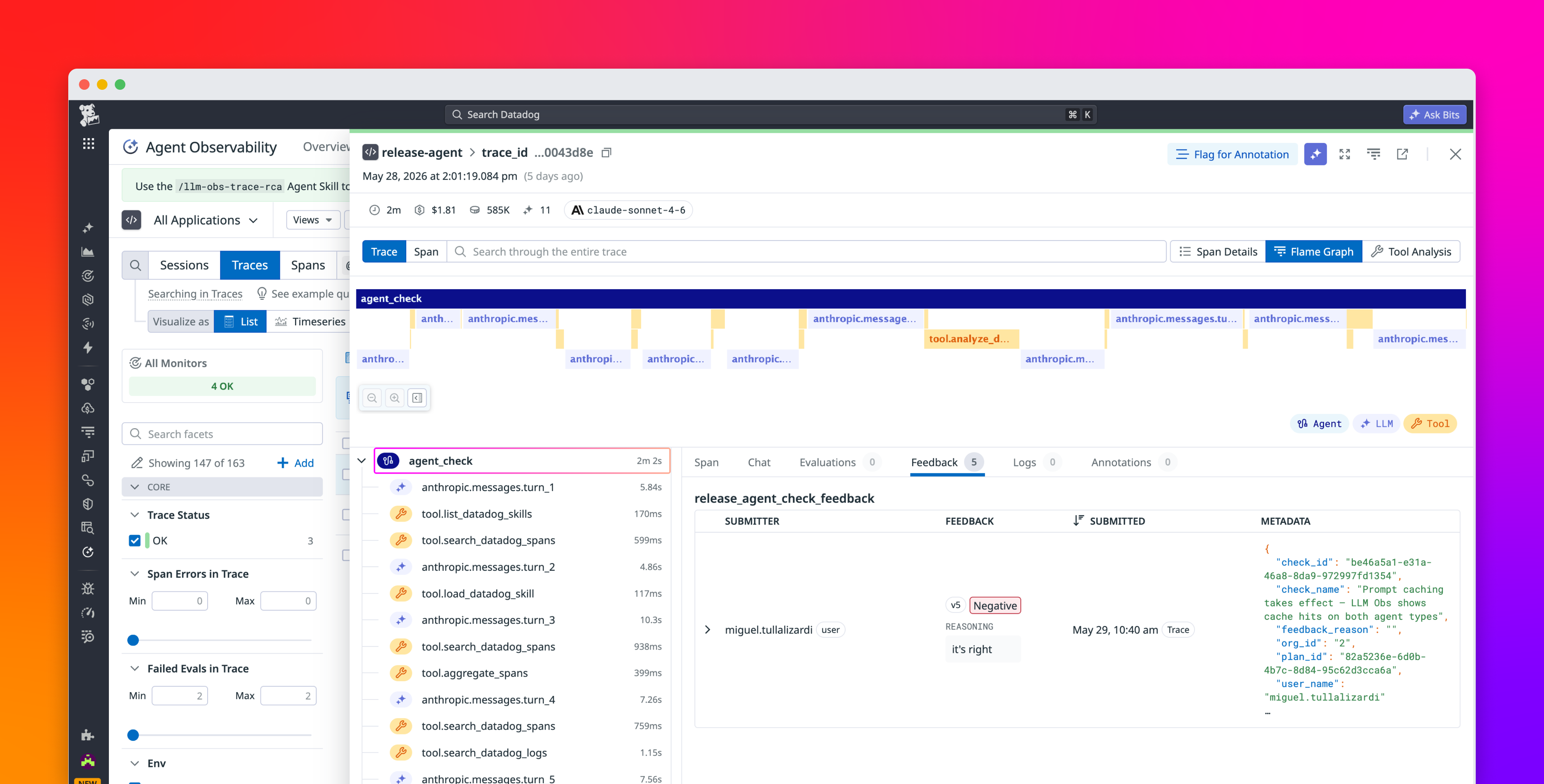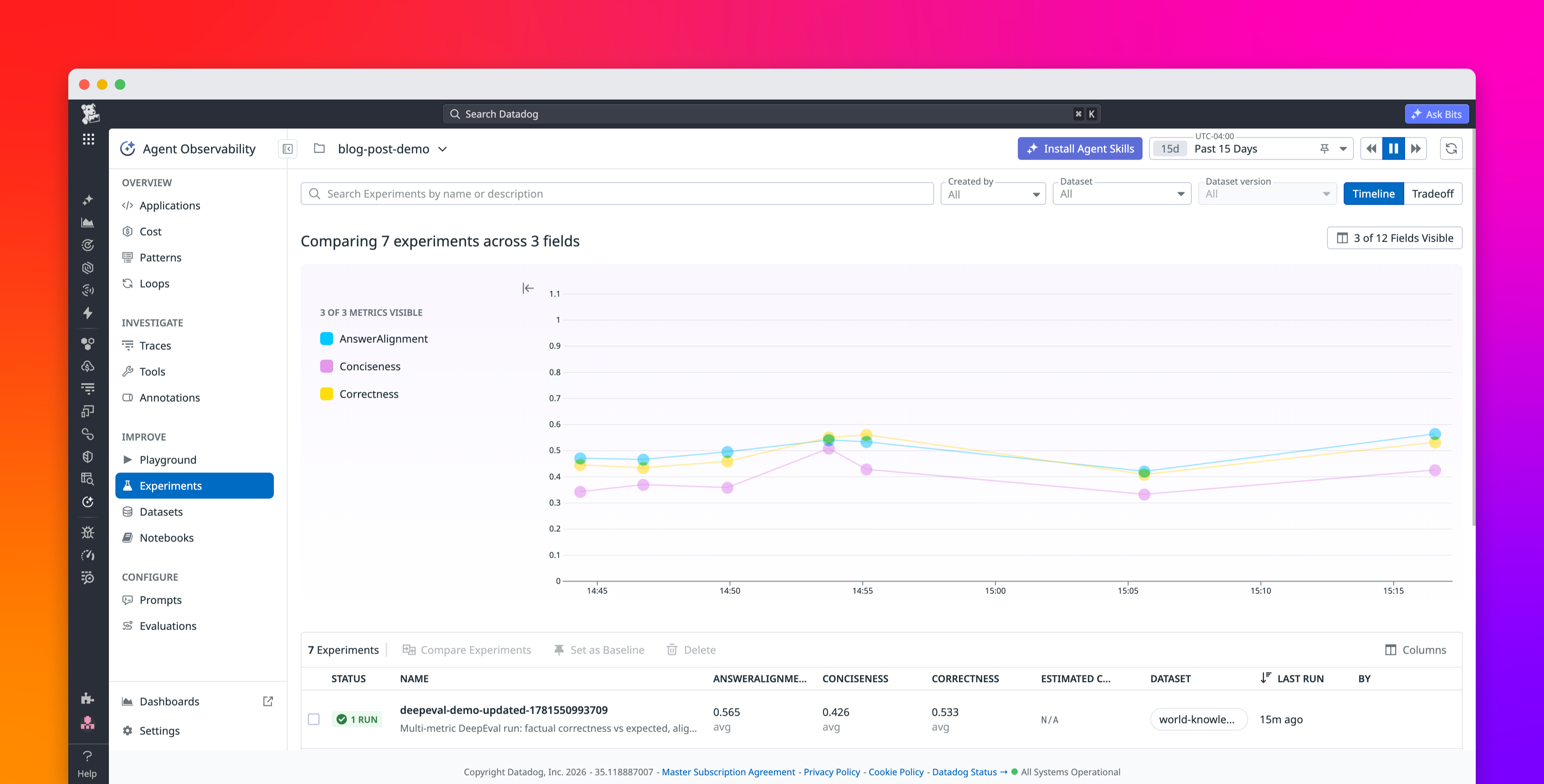
AI teams have invested heavily in evaluation frameworks, yet getting those frameworks beyond local experimentation remains challenging. Teams using open source libraries like DeepEval and Pydantic Evals gain flexibility and research-grounded metrics, but operationalizing those evaluations still requires brittle custom integration code that doesn’t scale. SaaS eval platforms often prioritize convenience, which can come at the cost of flexibility when teams need to port or extend their metric definitions over time. The result is that even mature teams with carefully tuned, task-specific evaluators end up with siloed artifacts: evals that work in a notebook, break in CI, and vanish entirely in production monitoring.
In this post, we explain how Datadog Agent Observability addresses this gap by letting teams run their existing DeepEval evaluations natively within Datadog Agent Observability Experiments. Datadog also supports Pydantic Evals, a code-first evaluation framework that provides its own dataset, evaluator, and LLM-as-a-judge primitives, for teams that prefer it or already use it alongside Pydantic AI. The examples in this post use DeepEval, but the same patterns also apply to Pydantic Evals. Together, these integrations give teams a single place to define, run, and monitor evaluation quality across every stage of development and deployment.