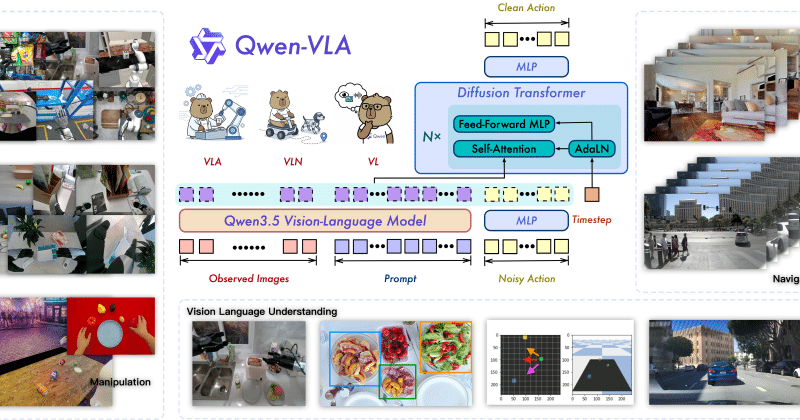
The Qwen team on Tuesday released a robotics suite featuring three foundation models: Qwen-RobotNav, Qwen-RobotManip, and Qwen-RobotWorld. These three models align language with different types of physical actions.
Qwen-RobotNav extends vision-language capabilities into mobile robotics through controllable observation encoding and tool-based interfaces. The model unifies four key tasks within a single framework: instruction following, goal-directed navigation, target tracking, and autonomous driving.
Qwen-RobotManip standardizes the state-action space and represents end-effector motion as incremental poses in the camera coordinate system. Trained on more than 38,100 hours of fully open-source data, the model supports large-scale learning across multiple robot platforms, enabling a broad range of manipulation capabilities.
Meanwhile, Qwen-RobotWorld serves as a general-purpose world model that connects vision-language understanding with future-state prediction through a natural-language action interface. The model can forecast physically consistent future outcomes across navigation, driving, and manipulation scenarios, allowing a single world model to generalize across diverse embodied AI tasks. [TechNode Reporting]