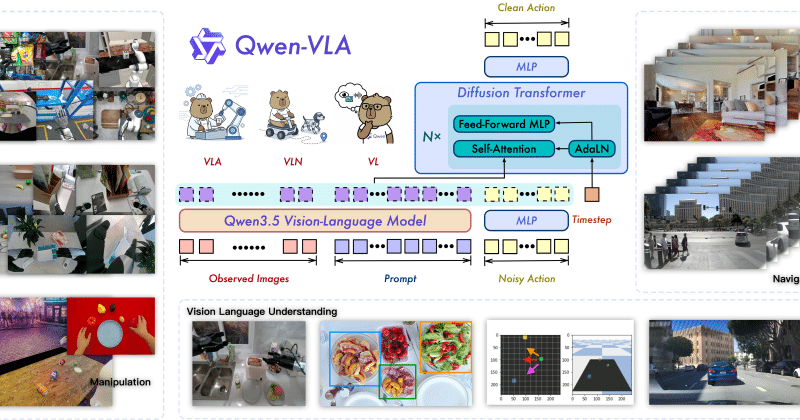
The Qwen team has released three embodied AI models, grouped as Qwen-Robot-Suite. The three are Qwen-RobotManip, Qwen-RobotWorld, and Qwen-RobotNav. Each is built on a Qwen vision-language backbone and targets a different robotics problem.
Qwen-RobotManip is a Vision-Language-Action model for manipulation, built on Qwen3.5-4B. Qwen-RobotWorld is a language-conditioned video world model with a 60-layer MMDiT and a frozen Qwen2.5-VL encoder. Qwen-RobotNav is a navigation model built on Qwen3-VL, available at 2B, 4B, and 8B sizes.
Qwen-Robot-Suite
Qwen-Robot-Suite is not a single model. It is a suite of three independent foundation models. Two of them, RobotManip and RobotNav, ship with public GitHub repositories.
Robotics data is fragmented across hardware and tasks. Different robots use incompatible observation and action formats. A policy trained on one arm rarely transfers to another.