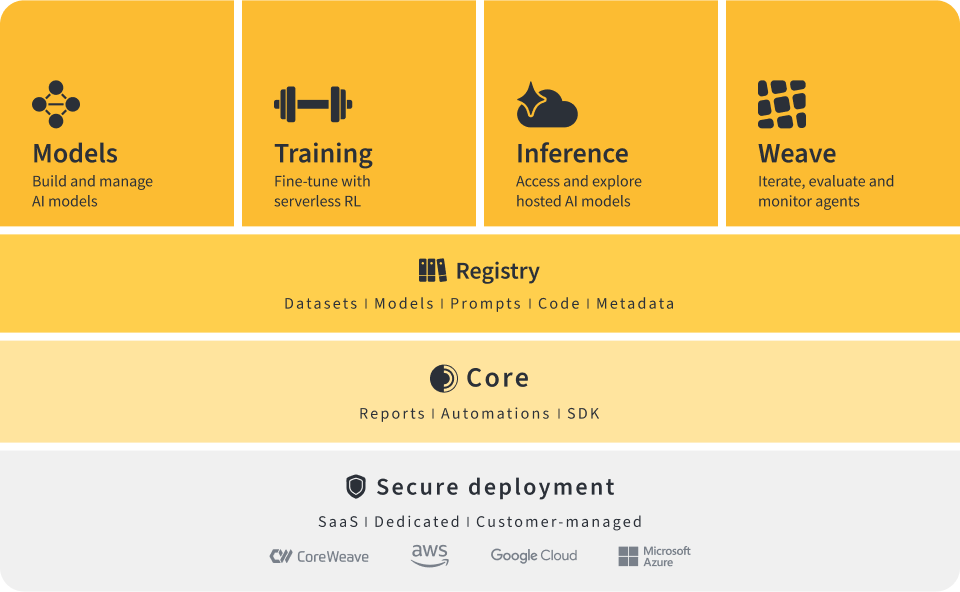
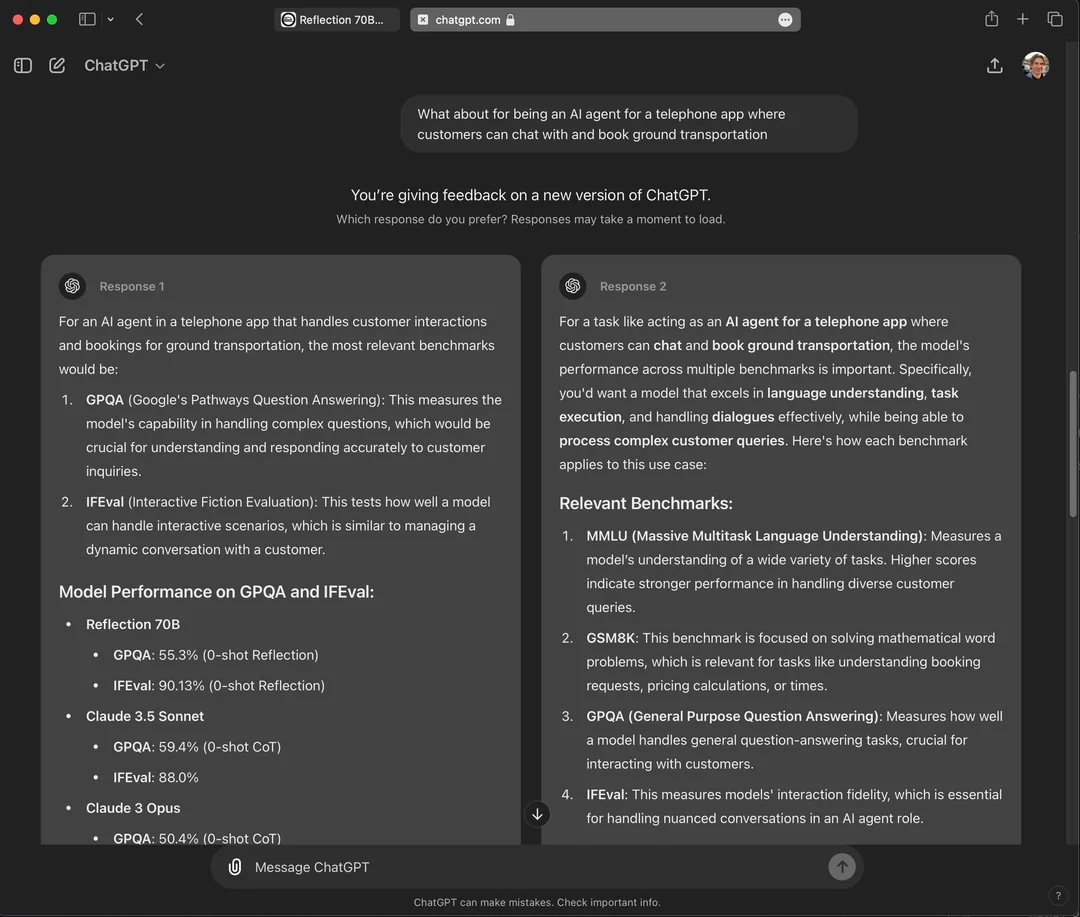
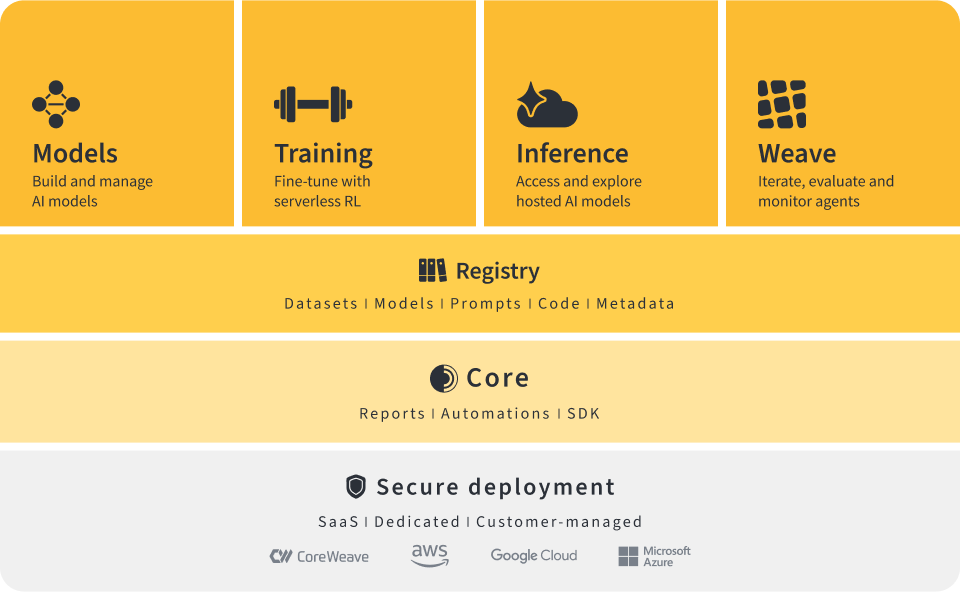
RLAIF is having a moment. Walk through any alignment paper or vendor pitch from the last six months and you'll see the same claim: replace your human labelers with a strong model acting as a judge, and you get most of the quality of Reinforcement Learning from Human Feedback at a fraction of the cost and none of the scheduling headaches. By most estimates the majority of enterprise LLM deployments now run some RLHF variant, and a growing share of that "H" is quietly becoming an "AI" — Reinforcement Learning from AI Feedback.
The economics are real. A model judge never sleeps, never disagrees with the rubric on a Friday afternoon, and scales to millions of comparisons for the price of inference. If you're tuning a chatbot to be a little more polite or a little less verbose, RLAIF is often the right call and you should use it.
But there's a quieter story underneath the hype, and it matters if you're shipping agents into anything that touches money, health, code, or safety. AI feedback is a multiplier on whatever judgment you already have. It is not a substitute for judgment you don't. The places where models-judging-models breaks down are exactly the places developers are now pushing agents hardest. Here's where the line actually falls, and how to think about it when you're designing a data pipeline rather than reading a press release.