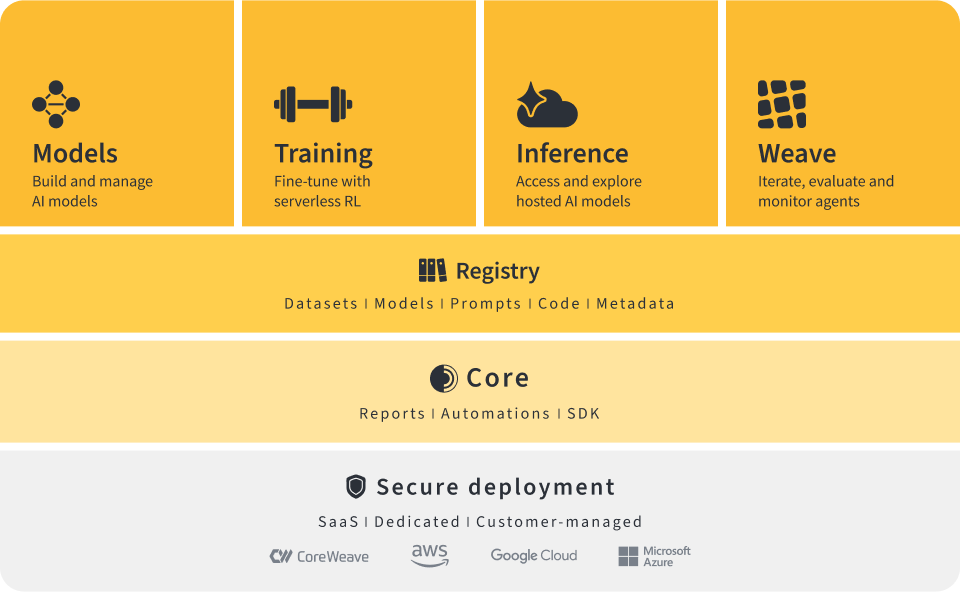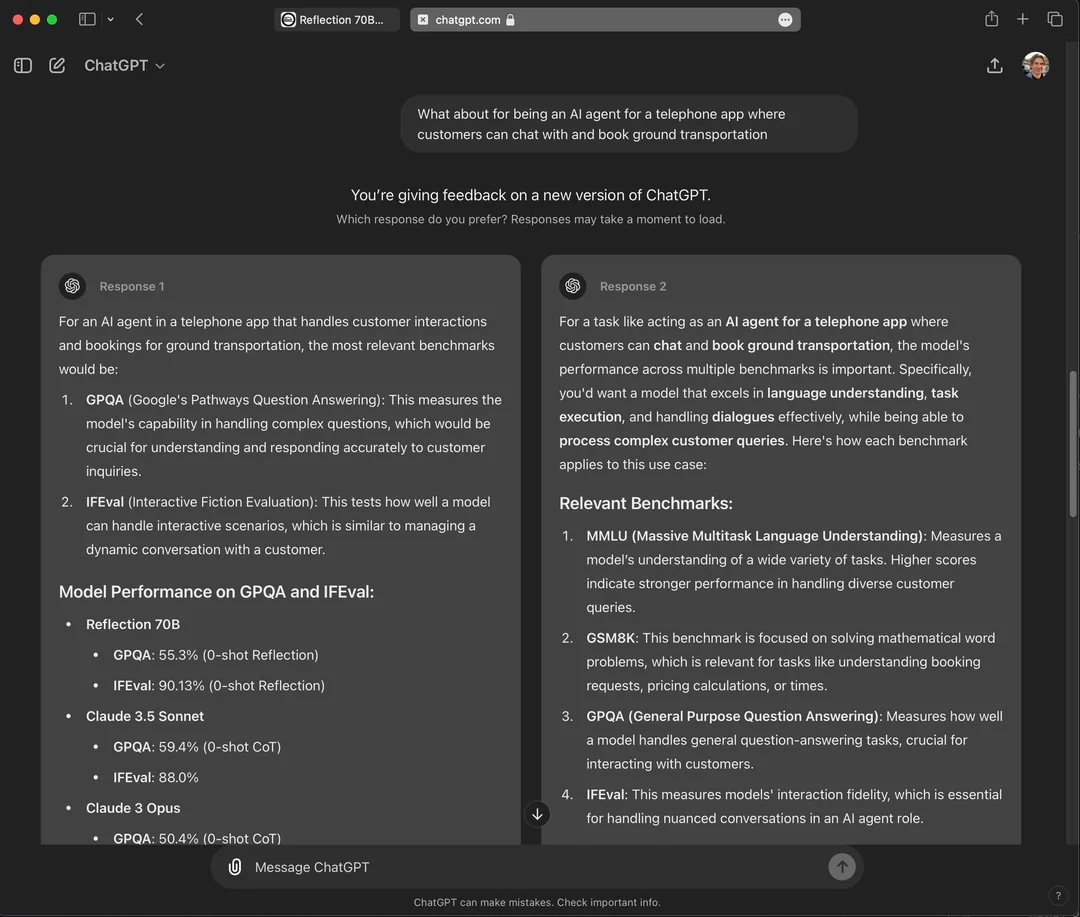
How does RLHF work in language models?Reinforcement learning from human feedback is a multi-stage process that adapts language models to better align with human expectations and preferences. Here is how RLHF typically works in the context of large language models:1. Data collection and supervised fine-tuningThe process begins with data collection, where humans interact with the language model and provide demonstrations of ideal responses to various prompts or questions. This feedback is used to create a high-quality dataset consisting of prompt-response pairs. The language model is then trained using supervised fine-tuning on this data, allowing it to learn and mimic human-like answers as a strong starting point.2. Human feedback and reward model buildingNext, the model generates multiple responses to a wide range of prompts. Human evaluators review these responses in pairs or sets and indicate which outputs they prefer. These preferences are collected and used to train a reward model, a separate neural network that learns to assign higher scores to responses more aligned with human feedback. This reward model serves as a proxy for direct human judgment, allowing the language model to be optimized in a scalable way.3. Optimization with proximal policy optimization (PPO)After the reward model is established, the language model is further trained using reinforcement learning, typically with an algorithm called Proximal Policy Optimization. The main objective in this phase is to update the language model so it generates responses that the reward model, informed by human preferences, considers high-quality.Reinforcement learning (RL) works by treating the language model as an agent that interacts with an environment (in this case, text generation based on prompts). For each prompt, the model generates a response, receives a reward score from the reward model, and updates its policy, the rules it uses to generate text, to increase the likelihood of producing high-reward responses in the future.A fundamental technique in reinforcement learning is the policy gradient method. In this approach, the “policy” is the probability distribution over possible outputs given an input. Policy gradient algorithms optimize this policy directly by estimating the gradient of expected reward with respect to the model’s parameters. Put simply, the algorithm adjusts the model’s weights so that responses that yield higher rewards become more probable over time.However, directly applying policy gradients can sometimes lead to unstable training or drastic changes in the model’s behavior, a problem known as “policy collapse.” Proximal policy optimization addresses this by introducing a constraint during updates. PPO ensures that the language model does not deviate too far from its previous behavior in a single update step. It does this by using a “clipped” objective function that limits the size of the policy update. This maintains a balance between making improvements and keeping the model stable and predictable.During PPO training, the process is typically as follows:The current language model (policy) generates responses to various prompts.The reward model scores these responses based on human preferences.PPO uses these scores to compute the advantage of each response, essentially grading how much better it is than expected.The policy (language model) is then updated to increase the likelihood of high-advantage, high-reward responses, but the update is limited to stay within a safe range of the previous policy.By repeating this loop, PPO gradually steers the language model to generate outputs that better reflect human feedback while maintaining training stability and preventing undesirable, extreme behaviors. This makes PPO a widely used and effective algorithm for aligning large language models with complex human goals through RLHF.4. Iterative improvementThis process of generating outputs, gathering human feedback, updating the reward model, and further optimizing the language model can be repeated to continually improve the model’s alignment with human values. By cycling through these steps, language models become more capable of producing outputs that are helpful, safe, and contextually appropriate.In short, RLHF in language models involves collecting human feedback to supervise the initial fine-tuning, building a reward model based on human preferences, and utilizing advanced reinforcement learning techniques, such as PPO, to optimize the main model for human-aligned performance. This multi-step framework enables language models to better understand and reflect the values, needs, and intentions of people using them.
What is RLHF? Reinforcement learning from human feedback for AI alignment
How does RLHF work in language models?Reinforcement learning from human feedback is a multi-stage process that adapts language models to better align with human expectations and preferences. Here is how RLHF typically works in the context of large language models:1. Data collection and supervised fine-tuningThe process begins with data collection, where humans interact with the language model and provide demonstrations of ideal responses to various prompts or questions. This feedback is used to create a high-quality dataset consisting of prompt-response pairs. The language model is then trained using supervised fine-tuning on this data, allowing it to learn and mimic human-like answers as a strong starting point.2. Human feedback and reward model buildingNext, the model generates multiple responses to a wide range of prompts. Human evaluators review these responses in pairs or sets and indicate which outputs they prefer. These preferences are collected and used to train a reward model, a separate neural network that learns to assign higher scores to responses more aligned with human feedback. This reward model serves as a proxy for direct human judgment, allowing the language model to be optimized in a scalable way.3. Optimization with proximal policy optimization (PPO)After the reward model is established, the language model is further trained using reinforcement learning, typically with an algorithm called Proximal Policy Optimization. The main objective in this phase is to update the language model so it generates responses that the reward model, informed by human preferences, considers high-quality.Reinforcement learning (RL) works by treating the language model as an agent that interacts with an environment (in this case, text generation based on prompts). For each prompt, the model generates a response, receives a reward score from the reward model, and updates its policy, the rules it uses to generate text, to increase the likelihood of producing high-reward responses in the future.A fundamental technique in reinforcement learning is the policy gradient method. In this approach, the “policy” is the probability distribution over possible outputs given an input. Policy gradient algorithms optimize this policy directly by estimating the gradient of expected reward with respect to the model’s parameters. Put simply, the algorithm adjusts the model’s weights so that responses that yield higher rewards become more probable over time.However, directly applying policy gradients can sometimes lead to unstable training or drastic changes in the model’s behavior, a problem known as “policy collapse.” Proximal policy optimization addresses this by introducing a constraint during updates. PPO ensures that the language model does not deviate too far from its previous behavior in a single update step. It does this by using a “clipped” objective function that limits the size of the policy update. This maintains a balance between making improvements and keeping the model stable and predictable.During PPO training, the process is typically as follows:The current language model (policy) generates responses to various prompts.The reward model scores these responses based on human preferences.PPO uses these scores to compute the advantage of each response, essentially grading how much better it is than expected.The policy (language model) is then updated to increase the likelihood of high-advantage, high-reward responses, but the update is limited to stay within a safe range of the previous policy.By repeating this loop, PPO gradually steers the language model to generate outputs that better reflect human feedback while maintaining training stability and preventing undesirable, extreme behaviors. This makes PPO a widely used and effective algorithm for aligning large language models with complex human goals through RLHF.4. Iterative improvementThis process of generating outputs, gathering human feedback, updating the reward model, and further optimizing the language model can be repeated to continually improve the model’s alignment with human values. By cycling through these steps, language models become more capable of producing outputs that are helpful, safe, and contextually appropriate.In short, RLHF in language models involves collecting human feedback to supervise the initial fine-tuning, building a reward model based on human preferences, and utilizing advanced reinforcement learning techniques, such as PPO, to optimize the main model for human-aligned performance. This multi-step framework enables language models to better understand and reflect the values, needs, and intentions of people using them.