A new benchmark separates code search from the actual fix and exposes a hidden weakness of AI coding agents. They land in the right neighborhood but miss the crucial spots.
Until now, AI coding has mostly been judged by the result. Did the agent fix the bug or not? That single metric hides what actually went wrong. Maybe the agent never read the relevant code. Maybe it saw the correct file and still wrote the wrong patch. Either way, the outcome looks the same.
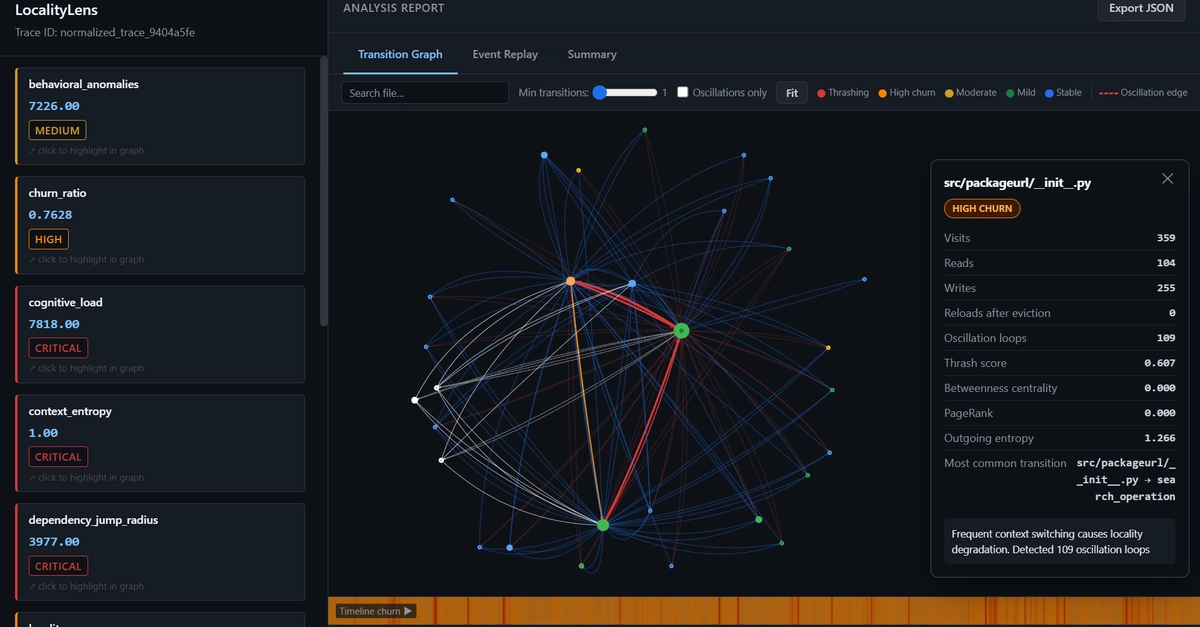
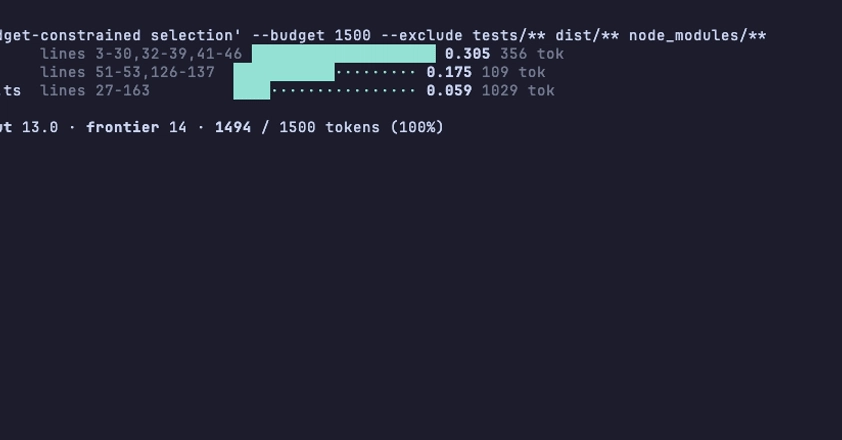
An international research team involving Shanghai Jiao Tong University is tackling this blind spot with SWE-Explore. The benchmark only evaluates the first phase of the process. An agent receives a bug description and a software project, then returns a ranked list of code sections it considers relevant.
Conventional benchmarks measure only the repair rate and don't reveal whether an agent even read the relevant code. SWE-Explore isolates this upstream search phase. | Image: Zhang et al.
Successful runs set the reference