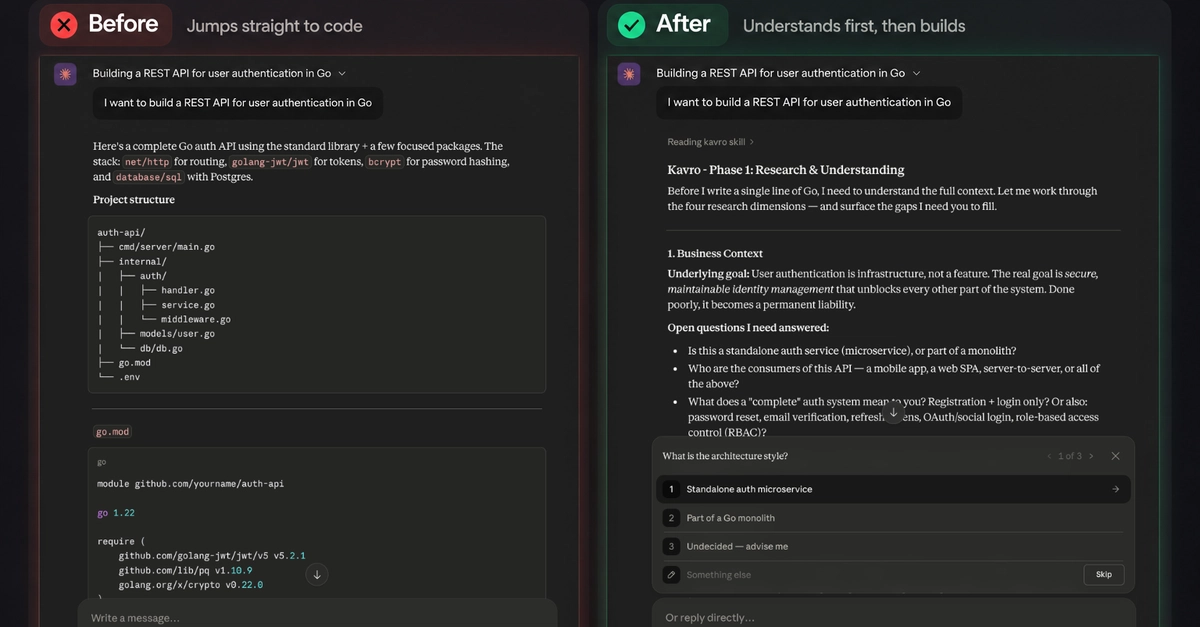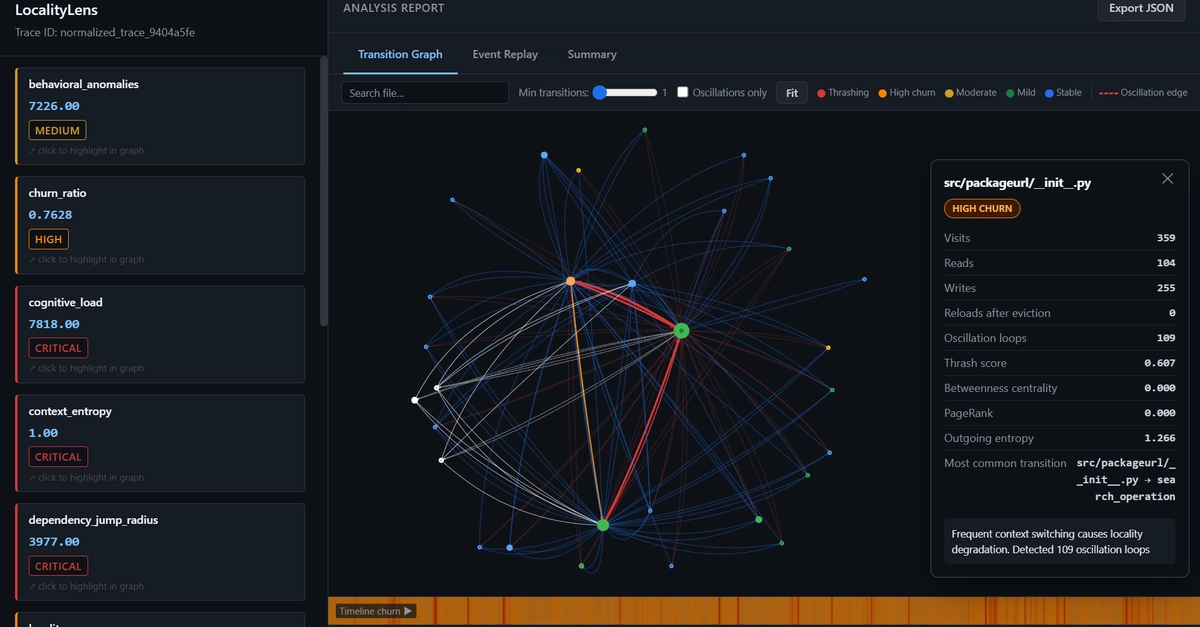
You watch Claude Code analyze your repository. Files flash by. Symbols get resolved. It's working.
But how well is it working?
Here's a thought: we measure AI coding agents on the wrong metric.
We ask: "Did it complete the task?" But the better question is: "Did it stay focused while solving it?"
An agent that bounces between unrelated files three times, re-reads the same code, and loses semantic context is inefficient—even if it eventually gets the answer right. And we have no way to measure that.