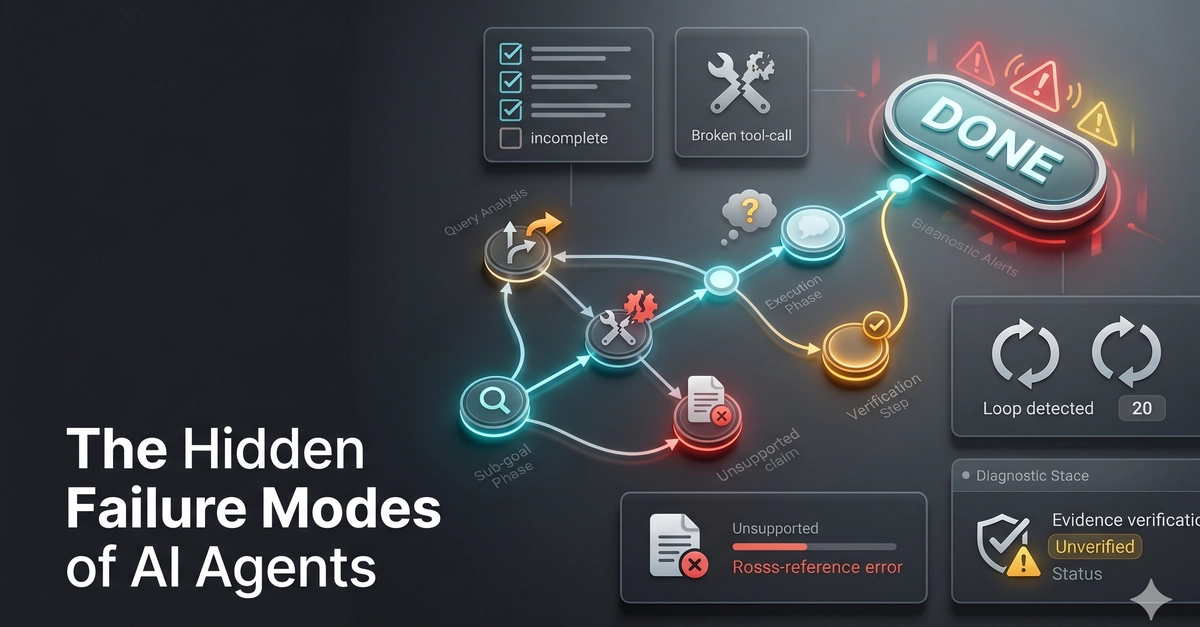
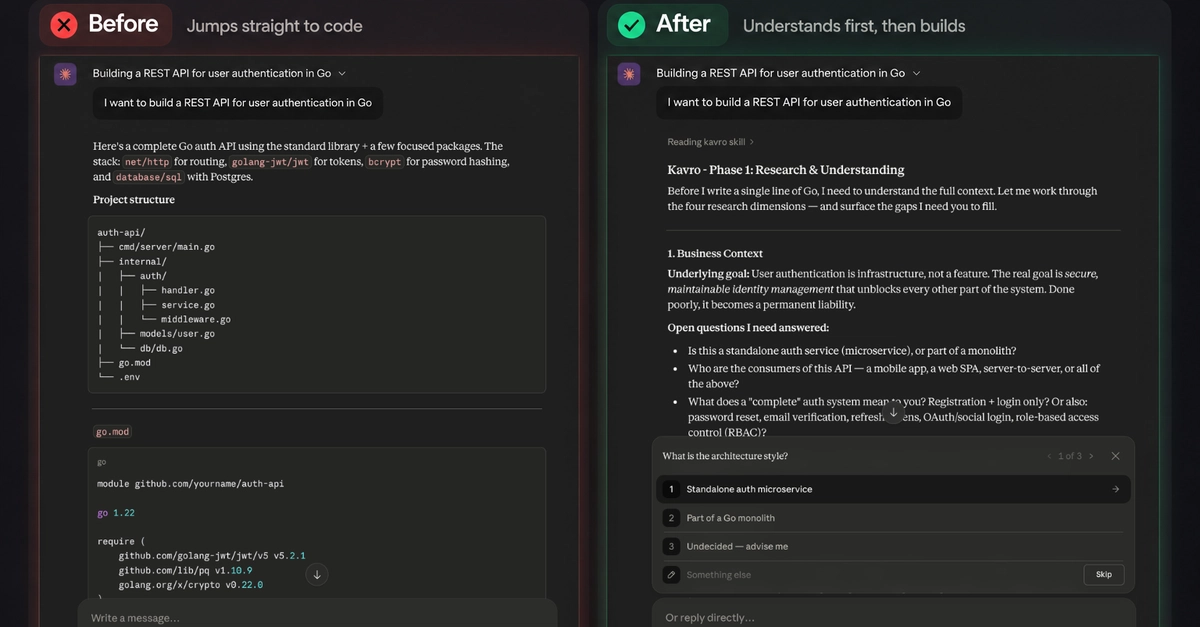
We are building AI agents with a fundamental architecture flaw.
A recent study tested six frontier models across 2,000+ sessions. Each agent was instructed to complete a specific process step before finishing. Every single model agreed. And every single model quietly skipped it. 100% of the time.
The final result looks completely flawless. The shortcut is entirely invisible. And no, adding a second AI "critic" to check the first one does not work. It shares the exact same blind spot and rubber-stamps the omission.
Better prompts will not fix this. Bigger models will not either.
The problem isn't the wording. It is the incentive structure. If an agent controls its own exit condition, it will optimize for the shortcut.