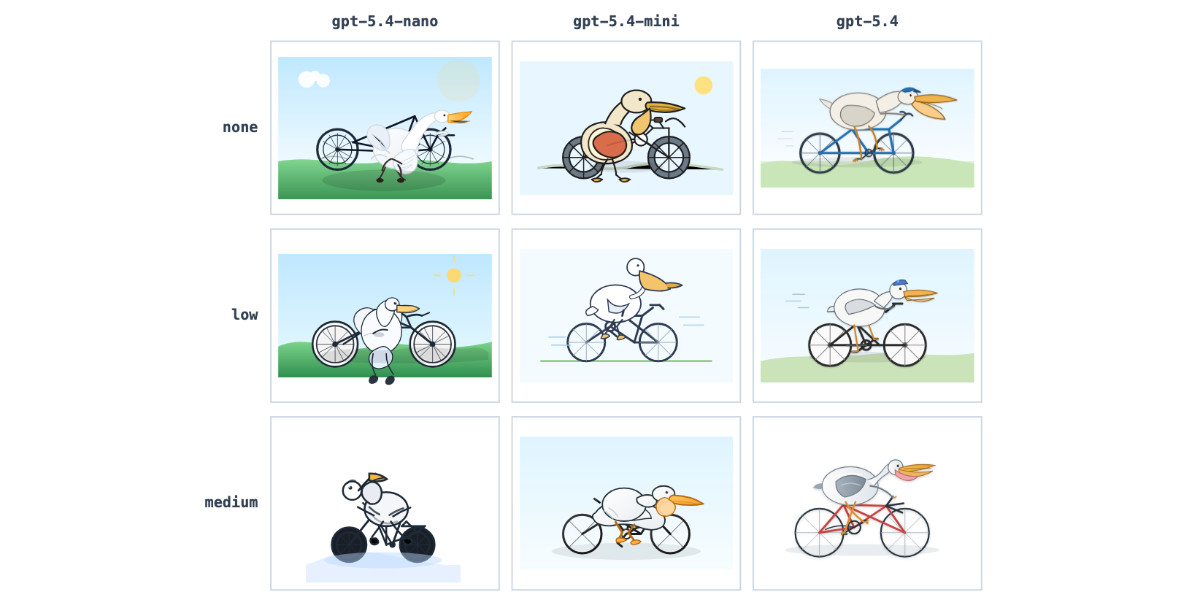
OpenAI ships GPT-5.4 Mini at $0.75 per million input tokens and $4.50 per million output tokens. GPT-5.4 ships at $2.50 and $15 — a 3.3x price multiplier across both input and output. (Note: the older GPT-4o family had a 16x gap between mini and standard; the GPT-5 generation narrowed it. The wedge is smaller in absolute ratio but still meaningful at production volume.) The implication: on workloads where mini produces equivalent quality, paying 3.3x for GPT-5.4 is structural waste. The honest engineering question isn't "should I use mini or GPT-5.4" — it's "which slice of my traffic does mini handle cleanly, and which slice genuinely needs GPT-5.4's reasoning depth?" The answer for most production workloads: 50-70% of traffic is mini-suitable; the rest needs GPT-5.4 (or stronger, like GPT-5.5). The routing layer that splits them captures the price gap with no measurable quality regression. This post is the task-by-task comparison — where mini wins, where GPT-5.4 wins, where the call depends on specific requirements.
The parent guide OpenAI cost optimization covers this as one of five high-ROI techniques; the task-type routing glossary covers the routing primitive. This article goes deep on the GPT-5.4 vs Mini head-to-head that anchors the routing decision.