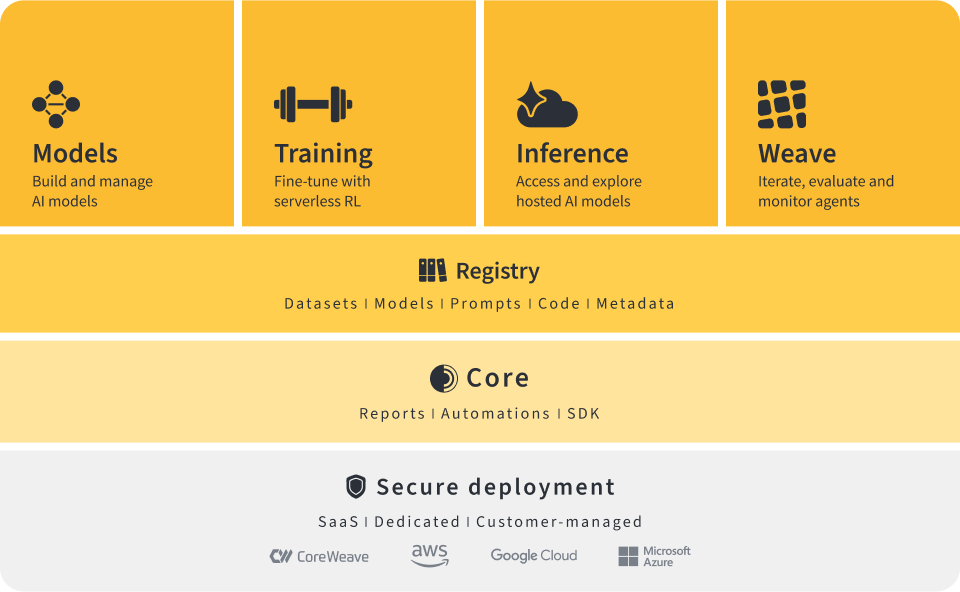
Introduction
AI agent systems are evolving rapidly. Today, we already see multi-agent architectures capable of solving complex problems by breaking them down into smaller tasks handled by specialized agents, each operating with its own context and responsibilities.
Multi-agent demos have become increasingly popular, showcasing impressive collaboration between agents. However, when designing a production-ready architecture, there is a fundamental principle that cannot be ignored: any component can fail.
In distributed environments, agents may become slow, unavailable, or respond with significant delays. External services, language models, and supporting infrastructure can all introduce failures that affect the overall workflow. If these scenarios are not considered during the design phase, a single failure can impact the entire system.
For this reason, resilient architectures must be designed to continue operating even when failures occur. When necessary, the system should degrade gracefully, temporarily reducing functionality while still delivering value to the end user. Building reliable AI agent systems requires not only intelligent agents but also the engineering practices needed to handle the realities of distributed computing.