Large language models can describe images, interpret charts, and pull text from photos. Multimodality is a given for modern AI systems. But one seemingly simple task remains surprisingly hard: reliably counting objects in an image.
Getting those counts right has real consequences, whether it's a doctor reading a scan, a farmer estimating crop yields, or a city planner analyzing traffic. Until now, each of these tasks has required its own specialized system.
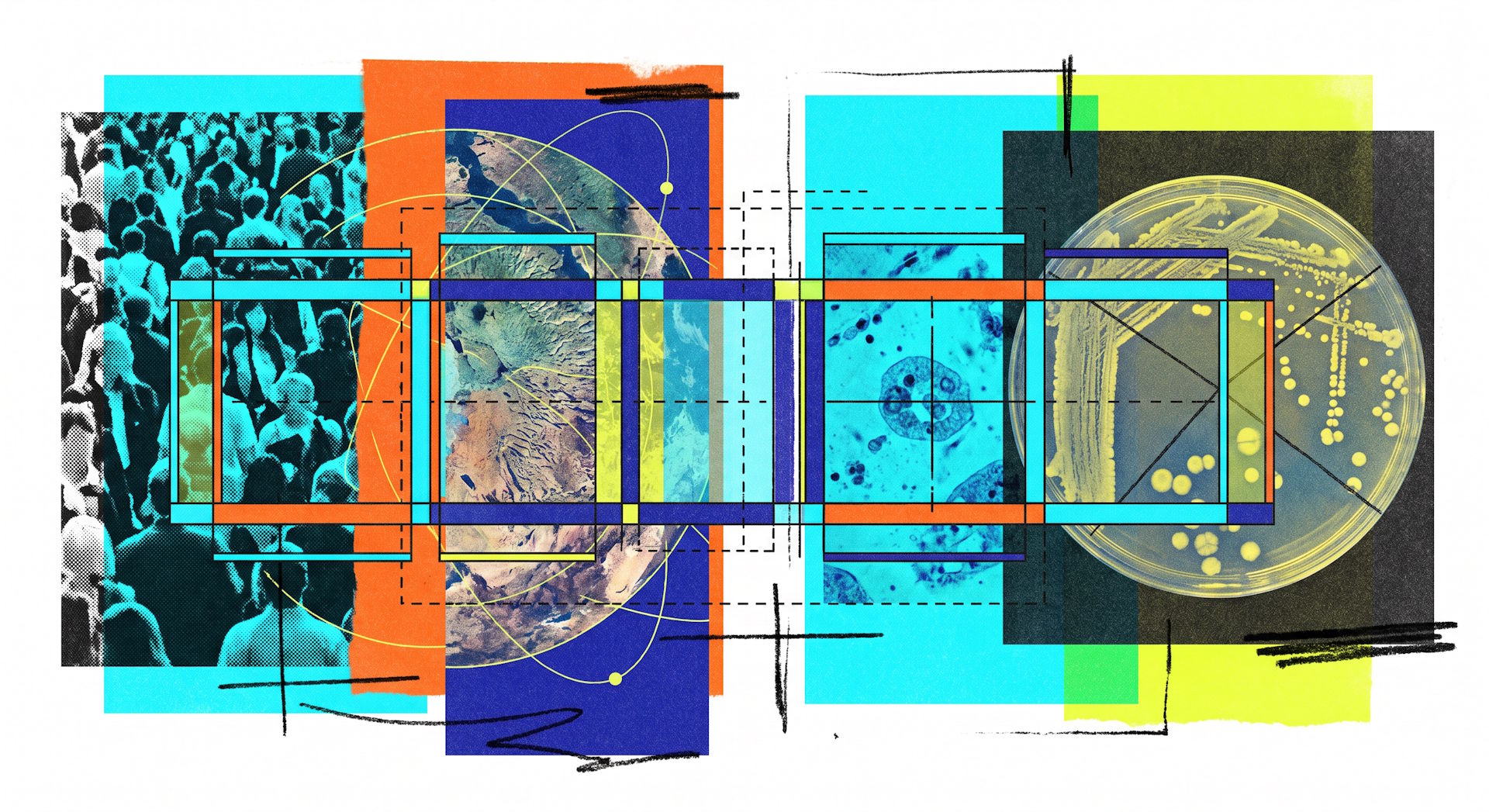
That's where "Count Anything" comes in. The new AI model from researchers at Tsinghua University and other institutions aims to count objects across very different types of images, whether that's heads in crowds, cars in satellite photos, cells in medical scans, or bacterial colonies in the lab.
It's a familiar problem. A system that reliably counts heads in a crowd often chokes on tightly packed cells under a microscope or tiny vehicles seen from above. The researchers want a single model that takes text input, marks every counted object in the image, and handles wildly different image types.
Two counters are better than one








