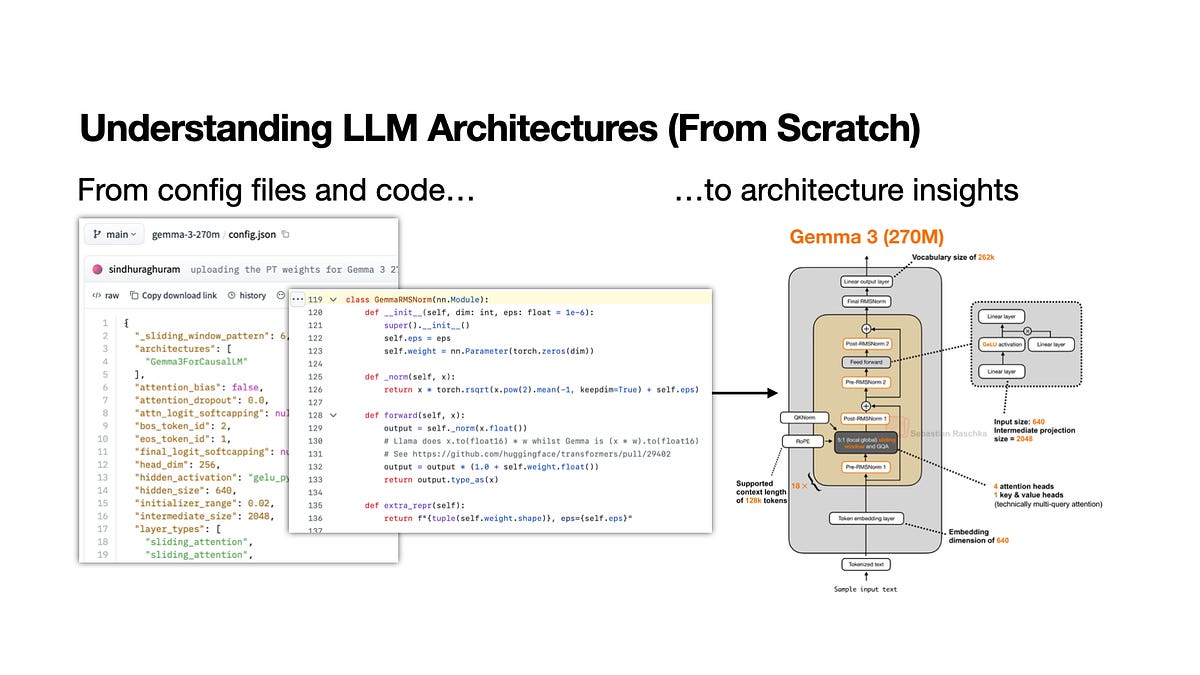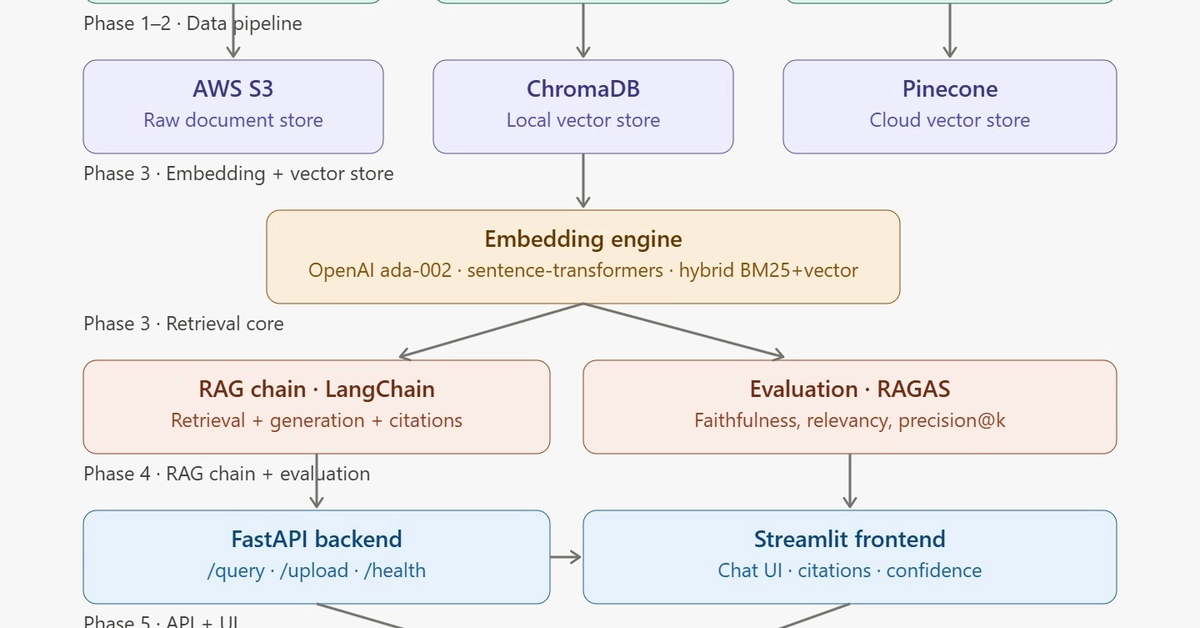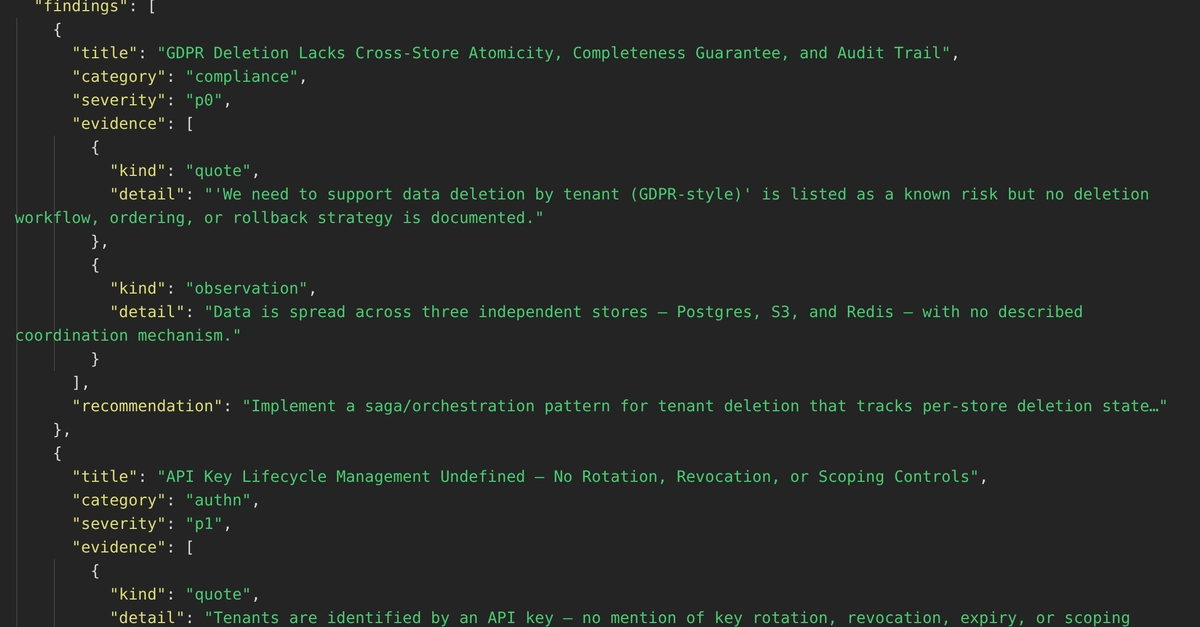
Architecture reviews have a translation problem.
Humans can leave a thread of “consider X” and “what about Y” and resolve the rest in a meeting. But if you want an LLM to participate in a workflow that resembles engineering - PRs, ADRs, ticketing, CI gates - fluent feedback isn’t enough. You need output that downstream systems (and humans) can reliably act on.
Most “LLM architecture review” demos stop at persuasive prose. The result reads like an experienced engineer, but it isn’t shaped like an artifact: it’s hard to rank, route, deduplicate, or turn into work without a second manual pass.
Multi-agent helps because architecture review is a bundle of lenses - security, scalability, operability, cost, data integrity, failure recovery - each with its own heuristics and thresholds. But the real differentiator isn’t “one agent vs. many”. It’s contracts. With PydanticAI, you define the schema the system must emit and validate every response; Claude supplies the reasoning, but the contract forces it into a machine-actionable shape.
This article shows how to build a multi-agent architecture reviewer that produces a structured review artifact: normalized findings with severity, evidence, and recommendations, plus clarifying questions and explicit “needs human judgment” flags. Think less chatbot, more review report.