Why I chose this topic:
I've seen too many evenings and weekends vanish debugging why a seemingly minor schema change in Kafka or Kinesis nuked a downstream dashboard, batch job, or real-time prediction model. The online docs often gloss over the gritty details of production-grade schema evolution, leaving practitioners to learn the hard way. This is about sharing those hard-won lessons.
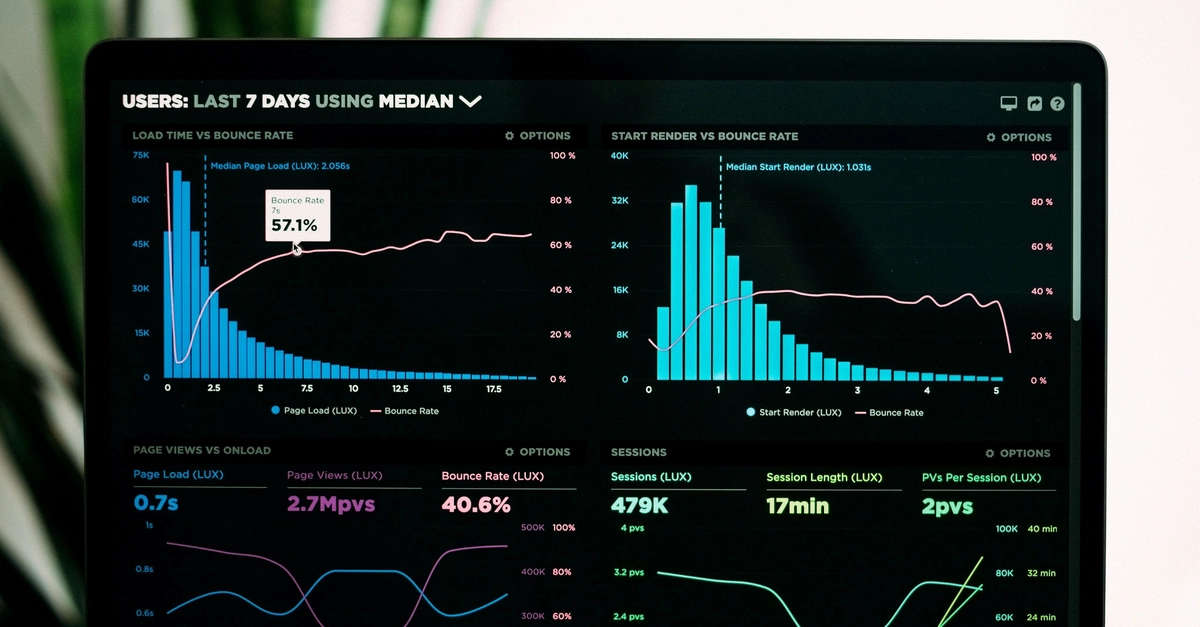
The pager went off at 3 AM. Not a good sign. A quick glance at Slack confirmed it: "Dashboard X is broken." Then another: "Batch job Y is failing." All traced back to a single Kafka topic. Someone, somewhere, had pushed a schema change. The symptoms were classic: deserialization errors, unexpected nulls, or worse, data that looked "right" but was subtly wrong.
We all know change is inevitable. Data models shift. Business requirements evolve. But in streaming pipelines, especially those handling critical financial or healthcare data, a "simple" schema change can be a cascade of failures. The promise of this article is to give you battle-tested strategies to evolve your streaming data schemas with confidence, ensuring your downstream consumers remain blissfully unaware of your behind-the-scenes work.
The real problem: It’s not just about the schema itself.