TL;DR — Most scraper "bugs" aren't bugs. They're the source site changing its data shape underneath you while your selectors and your code keep returning success. This is schema drift, and you cannot prevent it. You can only detect it. The detection has to be designed in. Here's how we do it.
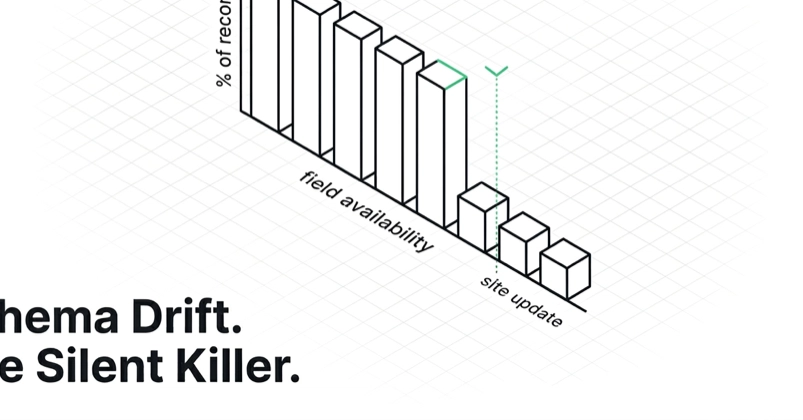
I have a low opinion of any scraper that does not log a per-field availability rate. It's the single most useful number you can produce, and almost nobody produces it.
The premise: every record you scrape has a set of expected fields. After every run, you compute, for each field, the percentage of records that had a non-null value for it. You log that number. You alarm on it.
That's it. That's the whole technique.
Why this matters