If you're learning data engineering, you'll probably meet Apache Kafka very early. You'll see it in job descriptions, system design diagrams, real-time analytics projects, fraud detection systems, and streaming pipelines. But Kafka can feel confusing at first because most explanations jump straight into brokers, partitions, and consumer groups before explaining the actual problem Kafka solves.
So let's start there.
Why Kafka Exists
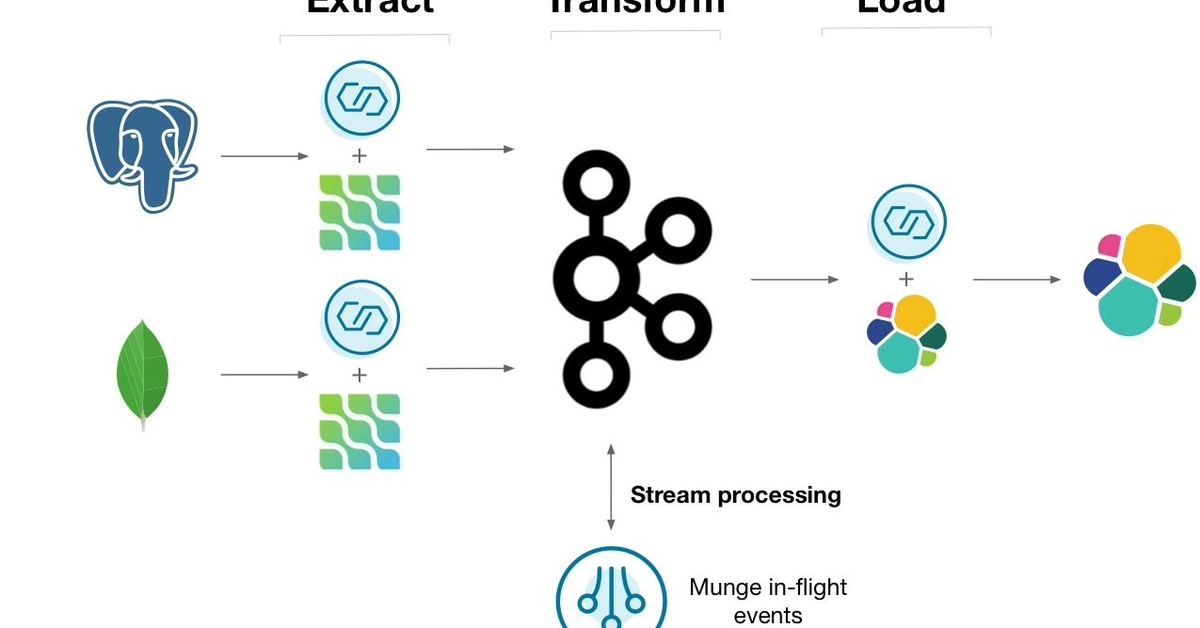
Traditional batch pipelines are built to answer one question: What does the data look like right now? Pull from the source, transform it, load it somewhere. Run it every hour, or every night. That works fine until you need to react to something the moment it happens.
A payment system that catches fraud after the transaction clears isn't catching fraud. A recommendation engine that updates overnight isn't personalizing anything in real time. A location tracking system that refreshes every hour is useless for logistics. These systems don't just need data. They need to know what's happening now, as events occur.