Designing a Scalable Event-Driven Data Processing Pipeline with Apache Kafka Streams
In modern data-intensive applications, real-time insights often drive user value. A robust event-driven data processing pipeline lets you ingest, transform, and route data with low latency while remaining resilient to failures and traffic bursts. This guide walks through designing and implementing a scalable, maintainable event-driven pipeline using Apache Kafka and Kafka Streams. It covers architecture decisions, data modeling, fault tolerance, deployment, and practical code examples you can adapt to your stack.
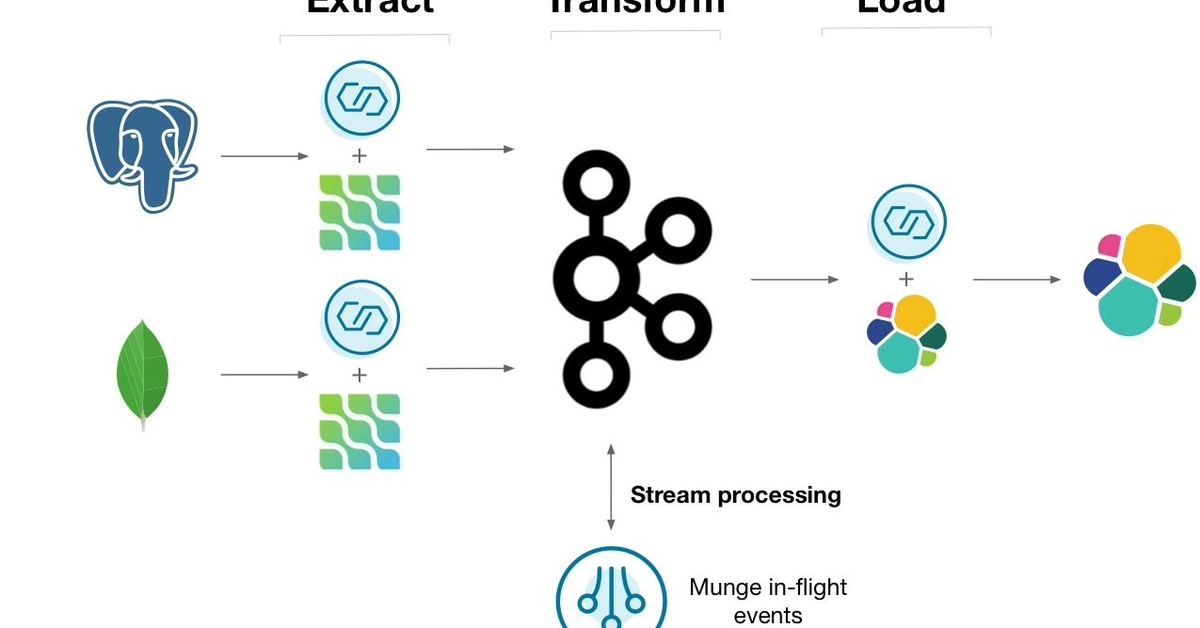
Overview of the architecture
Event producer layer: services that emit events in well-defined schemas.
Event broker: Apache Kafka clusters that persist events and decouple producers from consumers.