"Should I use RAG or an agent?" comes up in almost every LLM project I work on. The honest answer is that they are not competing choices. Classical RAG and agentic RAG sit on a spectrum, and picking the wrong end of it either wastes money or gives you weak answers. This post is a practical way to decide, based on a guide and demo I put together.
Repo with runnable code: https://github.com/ahmet-ozel/rag-architecture-guide
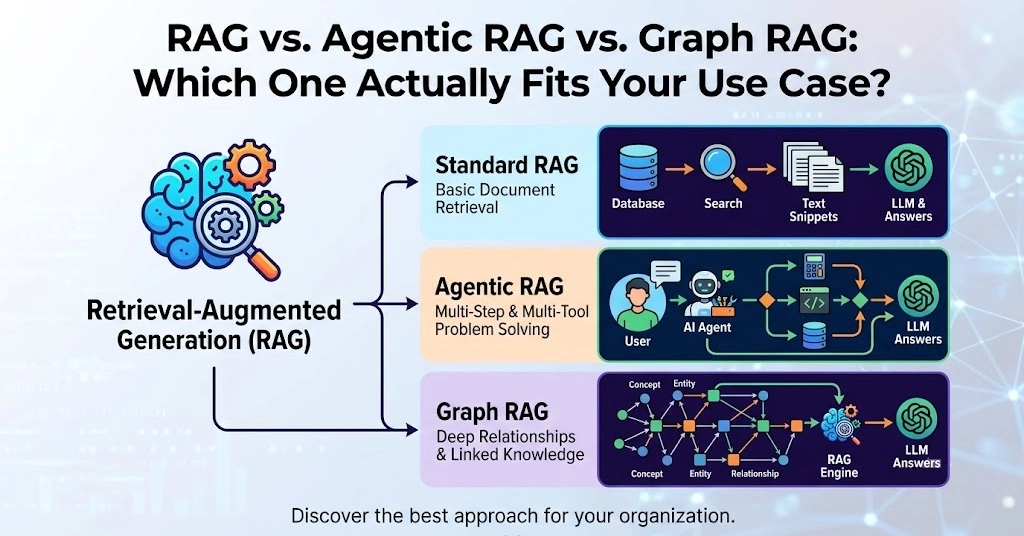
Classical RAG in one paragraph
Classical RAG is a fixed pipeline: embed the query, retrieve the top-k chunks from a vector store, stuff them into the prompt, and generate an answer. One retrieval, one generation. It is cheap, fast, and predictable. For a knowledge base where the answer lives in one or two documents, this is usually all you need, and adding anything more just increases latency and cost.
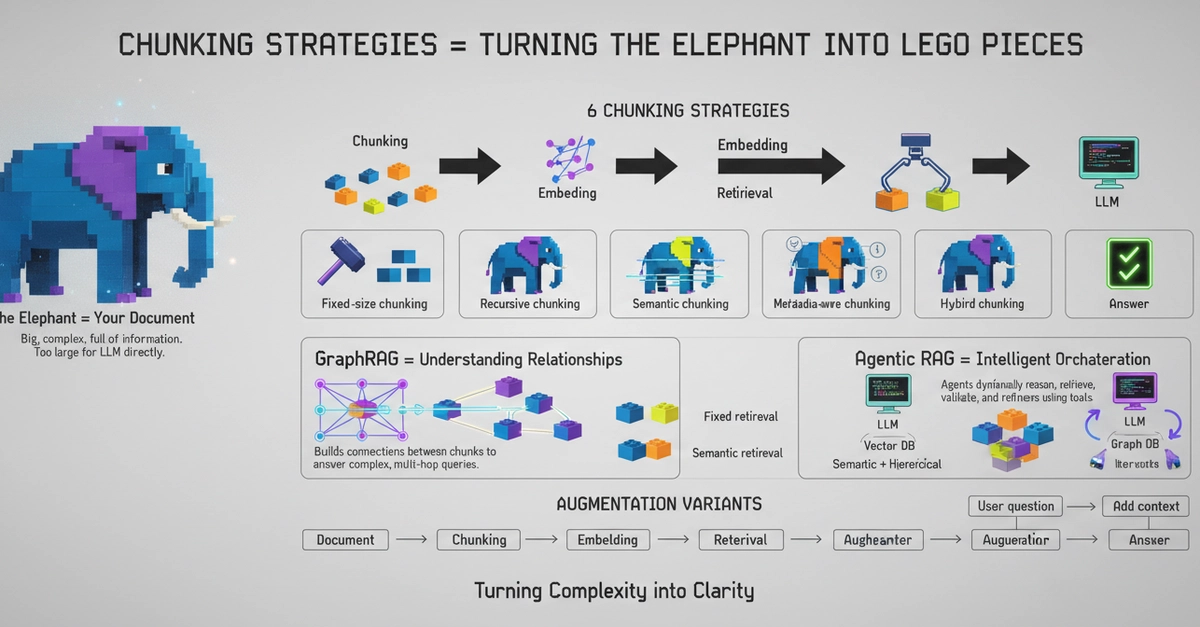
Agentic RAG in one paragraph