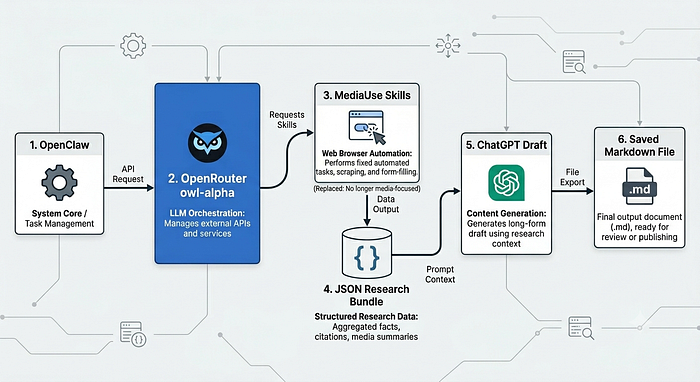
Introduction: The Challenge of Browser-Based Optimization
For years, the web has been a second-class citizen in the world of optimization. Solvers—the engines behind complex problem-solving in logistics, scheduling, and resource allocation—have traditionally required native environments. Their heavy computational demands and intricate algorithms simply couldn’t be efficiently translated to the browser. This wasn’t a theoretical limitation; it was a mechanical mismatch. Native solvers rely on direct hardware access, low-level memory manipulation, and multithreading capabilities that browsers historically lacked. Attempting to run these solvers in a web environment would either fail outright or result in performance so degraded as to be unusable.
The root of the problem lies in the architecture of browsers themselves. JavaScript, the lingua franca of the web, is single-threaded by design. While Web Workers allow for parallel processing, they’re isolated and communicate via message passing, introducing latency. Meanwhile, native solvers are built to exploit every ounce of CPU and memory, often using threads that share memory directly. This mismatch isn’t just about speed; it’s about feasibility. Without a bridge between these worlds, browser-based optimization remained a niche, impractical endeavor.