A new study suggests that instead of endlessly inflating models, it may be more efficient to increase the frequency of specific tasks in training data to anchor rare skills in smaller models.
A new study from researchers at Anthropic, Stanford, and other institutions explains why larger language models learn certain tasks that smaller ones fail at. The finding goes beyond the conventional wisdom that big models simply learn faster.
In some cases, small models can't reliably learn rare tasks even with extremely long training runs. Even well-known scaling laws show that a small model never reaches the loss of a large one, no matter how much data you throw at it.
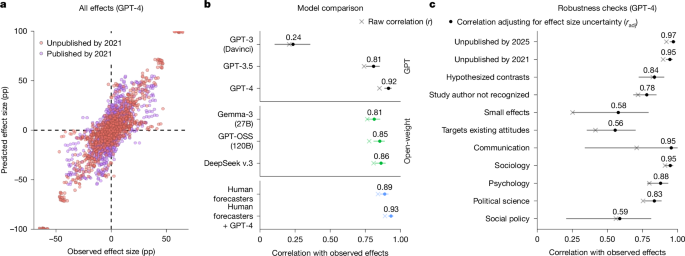
Only the larger OLMo models learn the rarely interspersed tasks reliably, as can be seen from the orange-colored fields at the bottom right of both tasks. | Image: Huang et al.
Common tasks crowd out rare ones