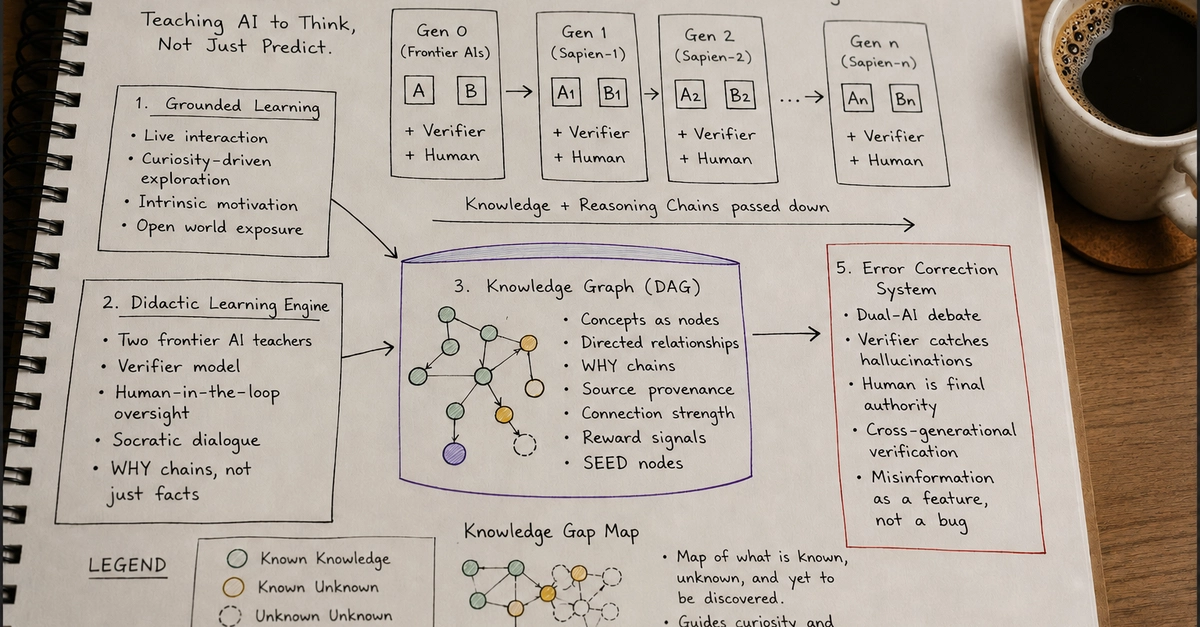
For today’s essay, I would like to cover an incredible paper with a provocative thesis and an even better title that I found myself reading multiple times last week: Language Models Need Sleep…. There’s an awkward fact about the models we all use every day: they don’t learn anything anymore. Whatever a frontier model knows, it learned once, during training, and then somebody hit save. After that it’s a brilliant fossil. It can reason circles around you about events up to its cutoff and then go completely blank about last Tuesday. You can stuff new facts into the context window, sure, but the moment the session ends, that knowledge evaporates like a dream you forgot to write down.Behrouz, Hashemi, and Mirrokni (Google + Cornell) have a name for this in their new paper, and it’s a good one: it’s anterograde amnesia. The patient with anterograde amnesia keeps every memory from before the injury and can hold a conversation in the moment, but nothing new ever makes the jump into long-term storage. Each day is experienced as if it were the first. Swap “injury” for “end of pre-training” and that is exactly the shape of a Transformer’s memory. It has the deep past (the MLP weights) and the immediate present (the attention cache), and almost nothing connecting them.The paper’s pitch is that we’ve been missing a step that biology figured out a long time ago. We sleep.
The Sequence AI of the Week #875: Why Your Language Model Needs a Nap
On “Language Models Need Sleep,” and the slow death of the train/test split
236 words~1 min read