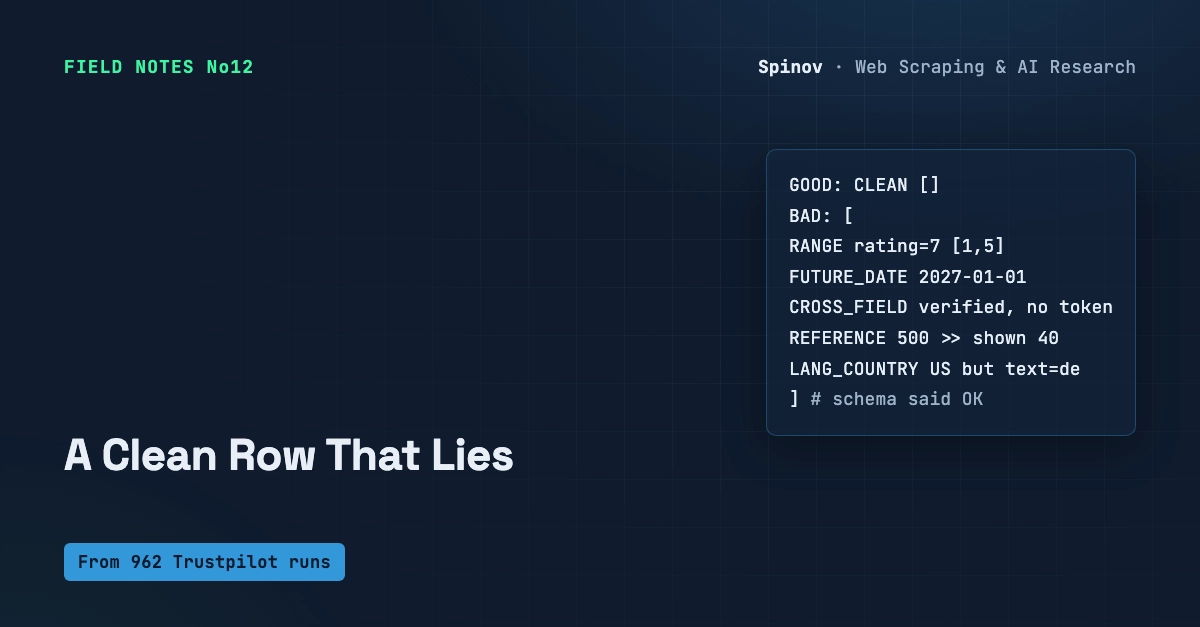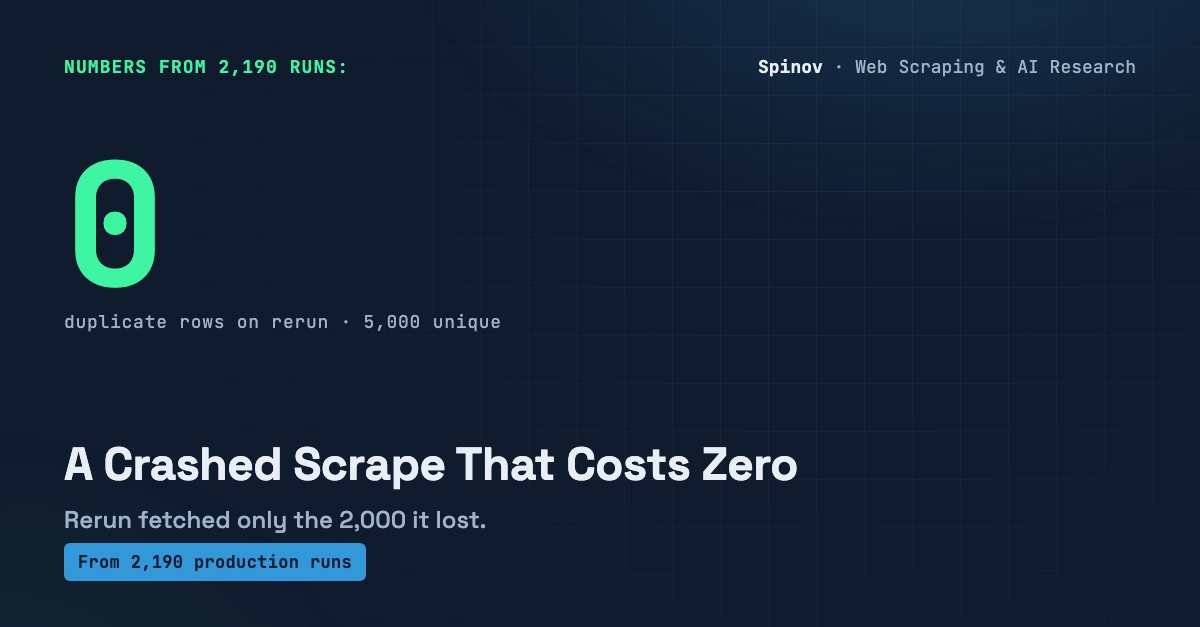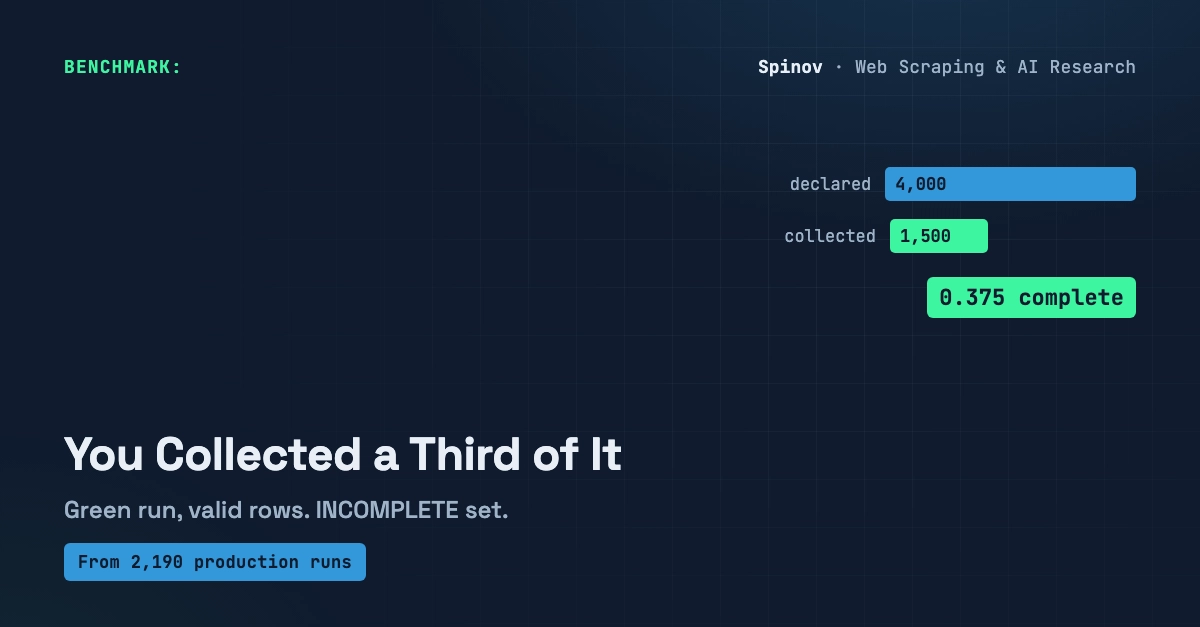
A scraper can pass every check you wrote and still be wrong about the one thing you actually care about: how much it collected.
No exception. No 500. No broken row. Exit code 0, logs green, every field valid. And the set on disk is a quarter of what the site actually has. I have run scrapers in production enough times to stop trusting a green run on its own, and this is the failure that taught me to count.
TL;DR
A paginated source can serve fewer rows than it claims and never throw — page caps, hidden offset limits, infinite scroll that "ends" early.
Your status check (200), schema check (valid row), and byte check (you got data) all pass. None of them counts records.