Note: This is a cross-post. Canonical version (full long-form) lives on my blog: https://blog.spinov.online/blog/ethical-scraping-is-a-rate-limit-question/
TL;DR
The "ethical scraping" debate keeps arguing about robots.txt and ToS. Those are real, but they're decisions you make once, before the first request. They tell you nothing about run 200, 600, or 900 — and that's where you actually load someone's server and where you actually get banned. (Good prompt for this post: Federico Trotta's "How to Scrape Open-Source Datasets Ethically" on The Web Scraping Club, May 24, 2026 — his line that a scraper "that would barely register as noise on Amazon's servers could genuinely degrade performance for a public data portal" is the part the robots.txt debate keeps skipping.)
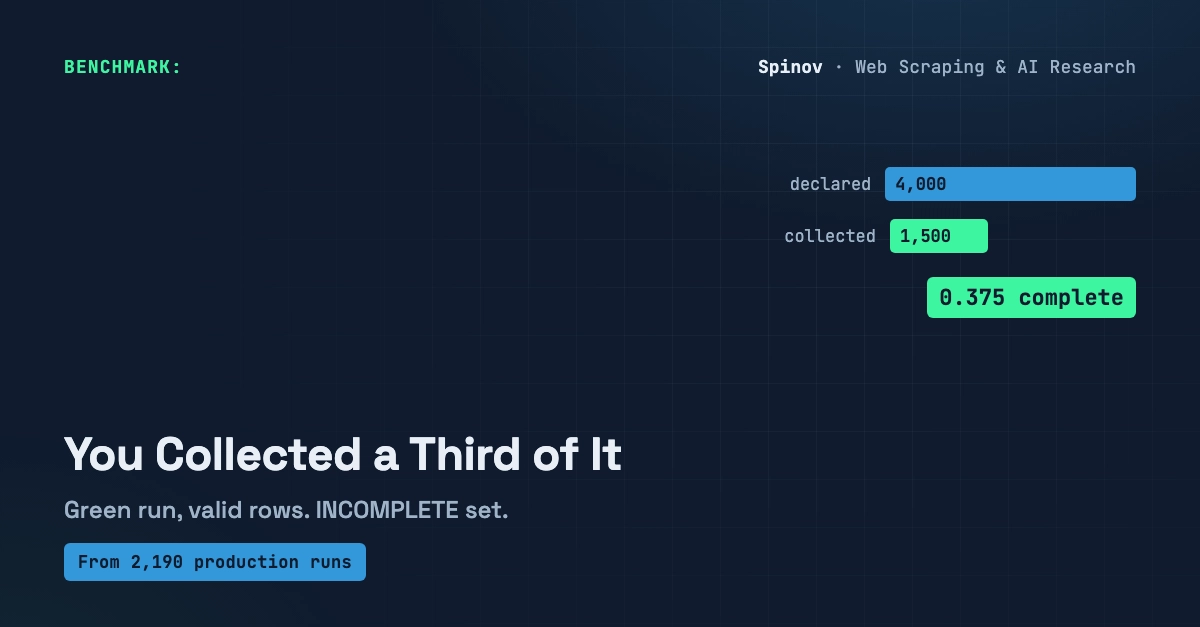
After 2,190 production scrapes across 32 scrapers (the busiest, a Trustpilot review scraper, has 962 runs on its own), I'm convinced of one thing: on a real schedule, "polite to the source" and "doesn't get banned" stop being two questions and become one. And the answer is mostly conditional GET plus a sane rate limit — not a robots.txt checkbox.
Where those numbers come from: my own Apify dashboard (apify.com/knotless_cadence), as of May 2026. 2,190 = total runs summed across my 32 published actors; 962 = the Trustpilot scraper's own lifetime counter. Raw platform numbers, not sampled or extrapolated.