A scraper that returns HTTP 200 is not a scraper that returns good data. Those are two different claims, and almost every monitoring setup I've seen conflates them.
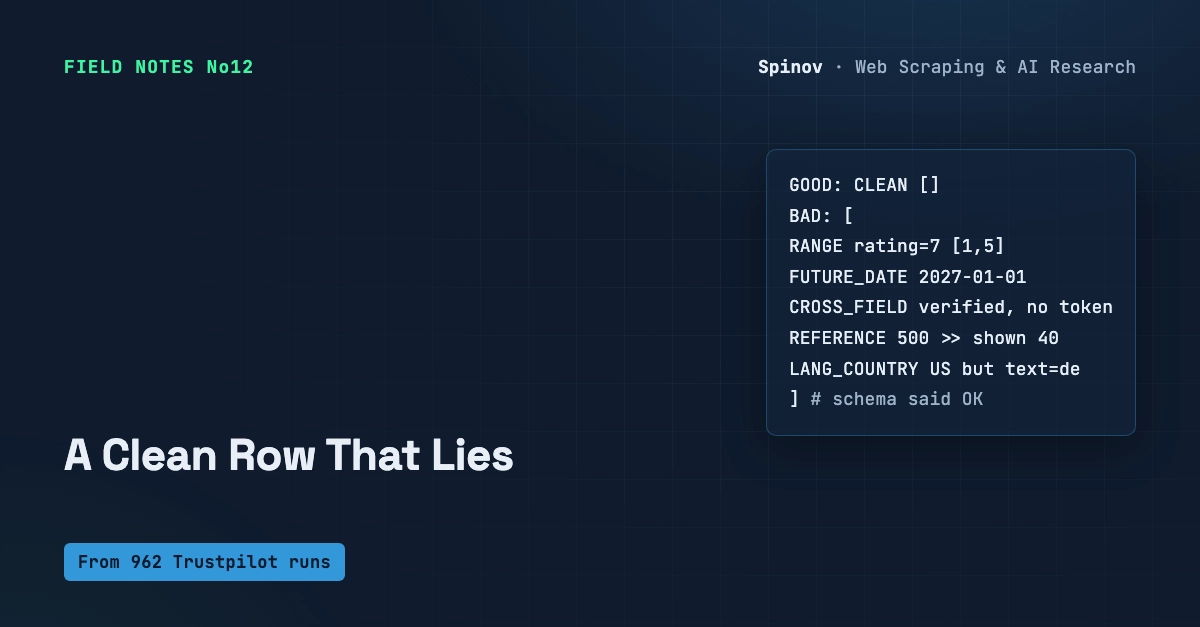
Here's the failure mode nobody writes code for. The source you scrape quietly changes. A field gets renamed, a number comes back as a string, one column goes blank. Your request still gets a 200. Your parser doesn't throw. Your job exits green. And from that day forward, every scheduled run feeds slightly-wrong records into your corpus. No alarm. No stack trace. Just slow rot.
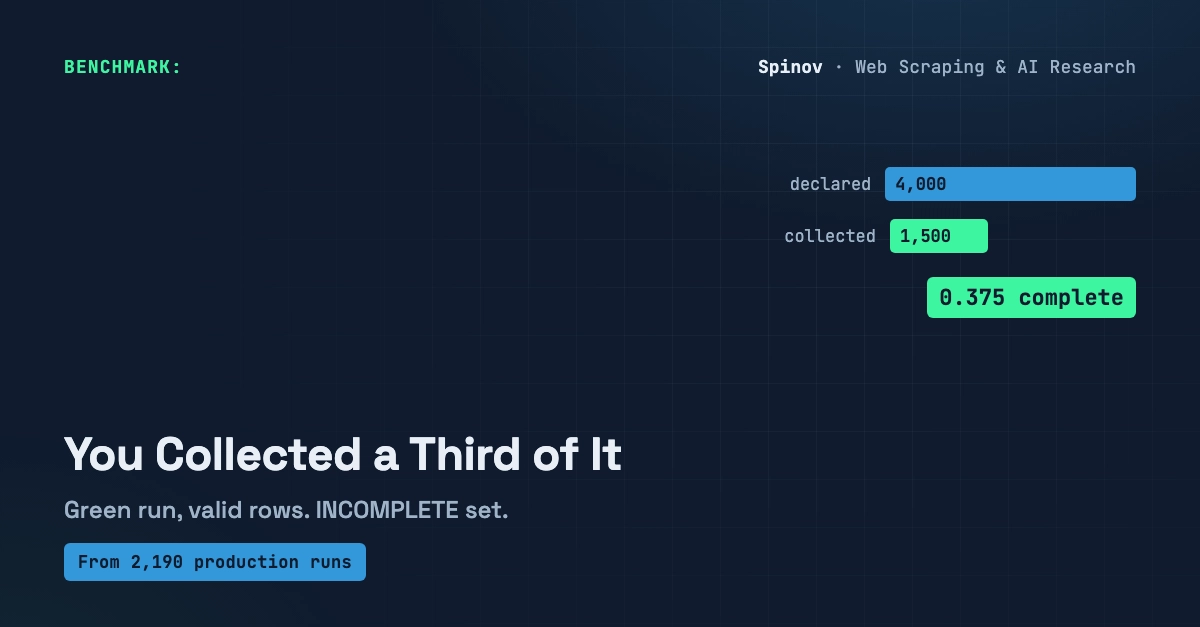
I've got 2,190 production scraper runs behind me, 962 of them on a single Trustpilot review scraper (that's a raw lifetime run counter on my Apify profile, knotless_cadence, as of May 2026; not a controlled study, just a long-running meter). And the thing I learned running one source that many times isn't about proxies or rate limits. It's this: the most expensive failures are the ones that don't fail.
This post is about catching them cheap. There's a 30-line stdlib validator at the bottom. Copy it, run it, drop it into your pipeline today.
TL;DR