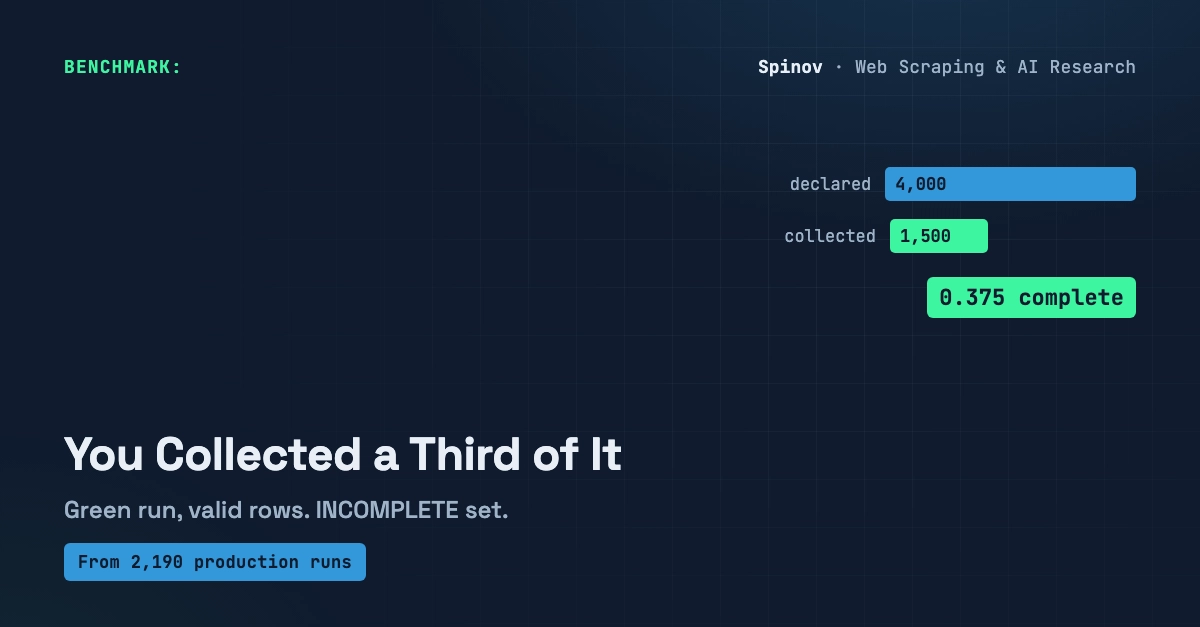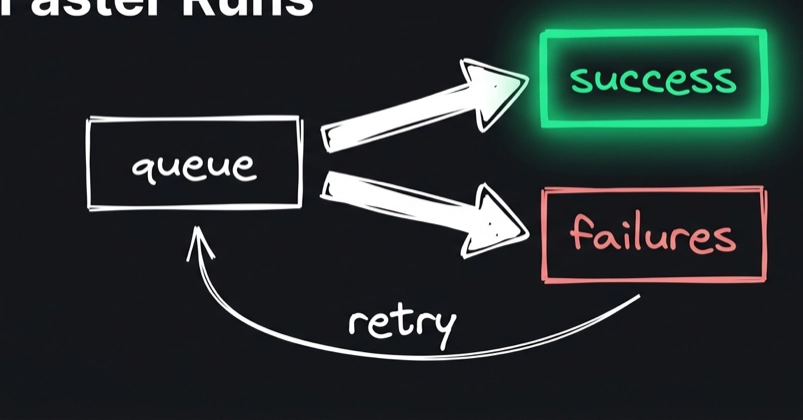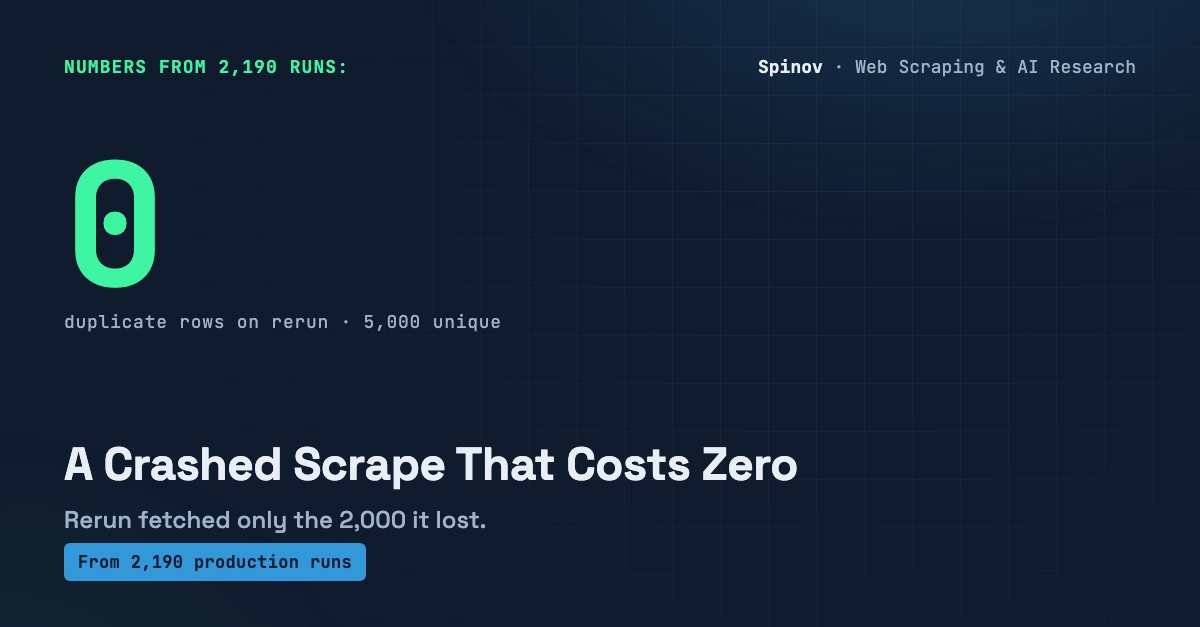
My scraper died at row 12,000 of 50,000, three hours in. The crash itself was cheap. A process gets OOM-killed, a quota trips, a machine reboots, it happens. The expensive part came next: I re-ran it. From zero. And paid, in time and in requests, for the 11,999 rows I already had sitting on disk.
That second bill is the one nobody writes code for. This post is the code. It's about 40 lines of stdlib Python that let a crashed job pick up where it died, fetching only the missing rows and writing zero duplicates, plus the real captured output of a run that crashes and a rerun that finishes it cleanly.
To be clear about scope: this is the run after the crash — how to restart a long job so it finishes the work it lost without re-fetching what it already pulled and without writing a row twice. It is not retry/backoff inside a single request (that's a different post of mine), not schema-drift detection (the post where I said "a crash loses the run" — this is the part where you get the run back), not a budget kill-switch that stops a runaway, and explicitly not conditional-GET / ETag / "skip unchanged pages" — that's freshness, a separate question entirely. Just: your job died mid-way, the clock and the bill are still running, how do you resume cheap and clean.