robots.txt parsing looks like a weekend job. It is a flat text file. Each line is a directive. You split on the colon, match the user agent, check whether a path is disallowed. How hard can it be.
Then you start feeding it real files. You hit a group that opens with three User-agent lines and one rule block. You hit a Disallow: /*? that means more than its author thought. You hit a file that 404s over HTTPS but loads over HTTP. You hit comments mid-line, mixed casing, and a Disallow: with nothing after it. The weekend job grows teeth.
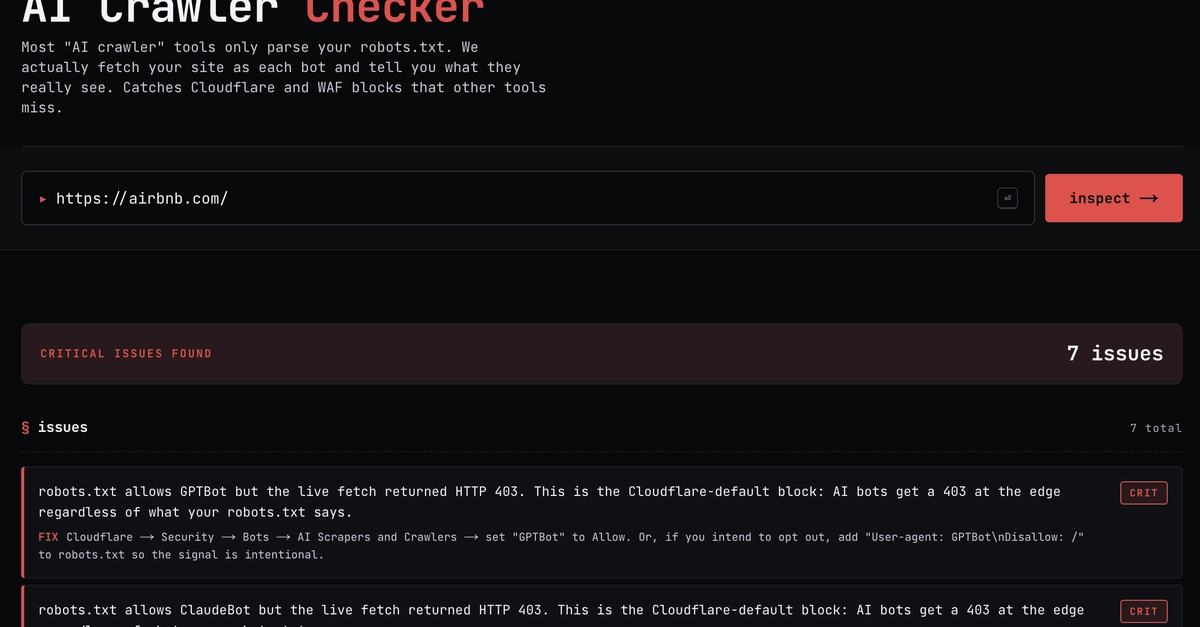
We built the AI Crawler Checker to answer one narrow question well: for a given domain, which of the major AI crawlers can read it, and which cannot. We grade against ten specific user agents:
GPTBot: ChatGPT and OpenAI, training and search
ChatGPT-User: ChatGPT live browsing