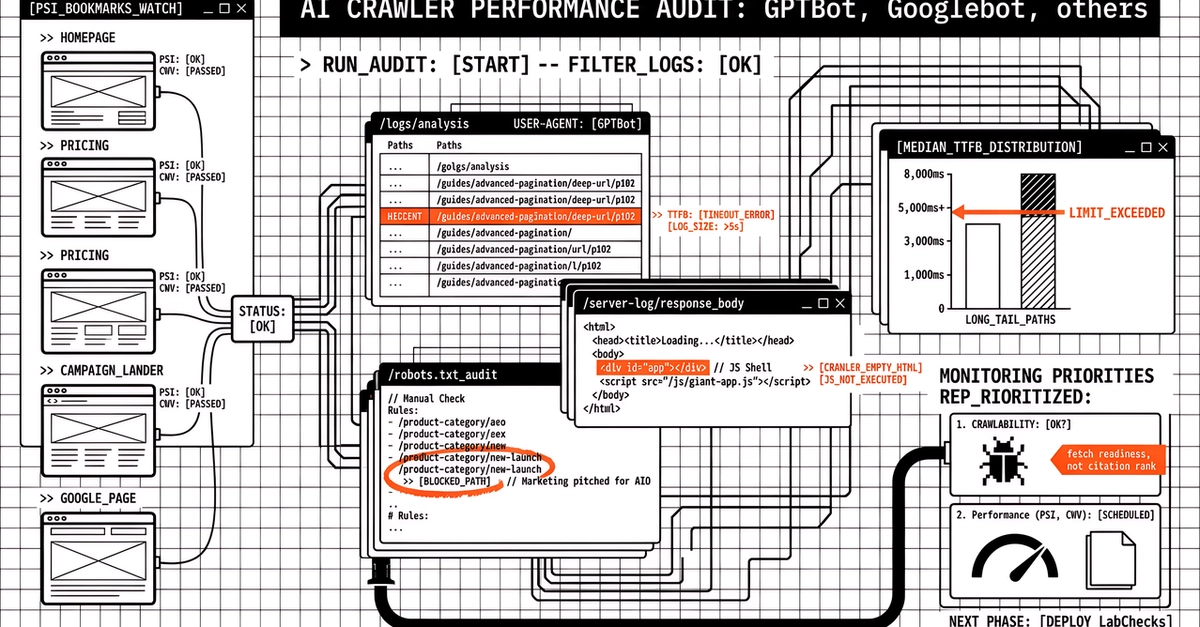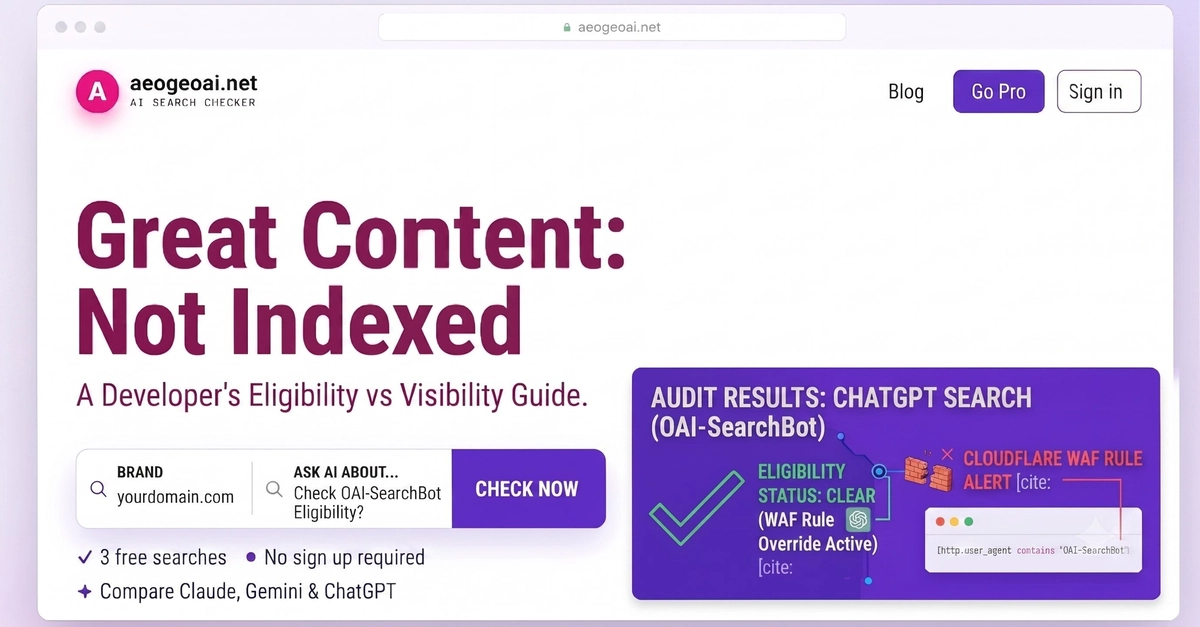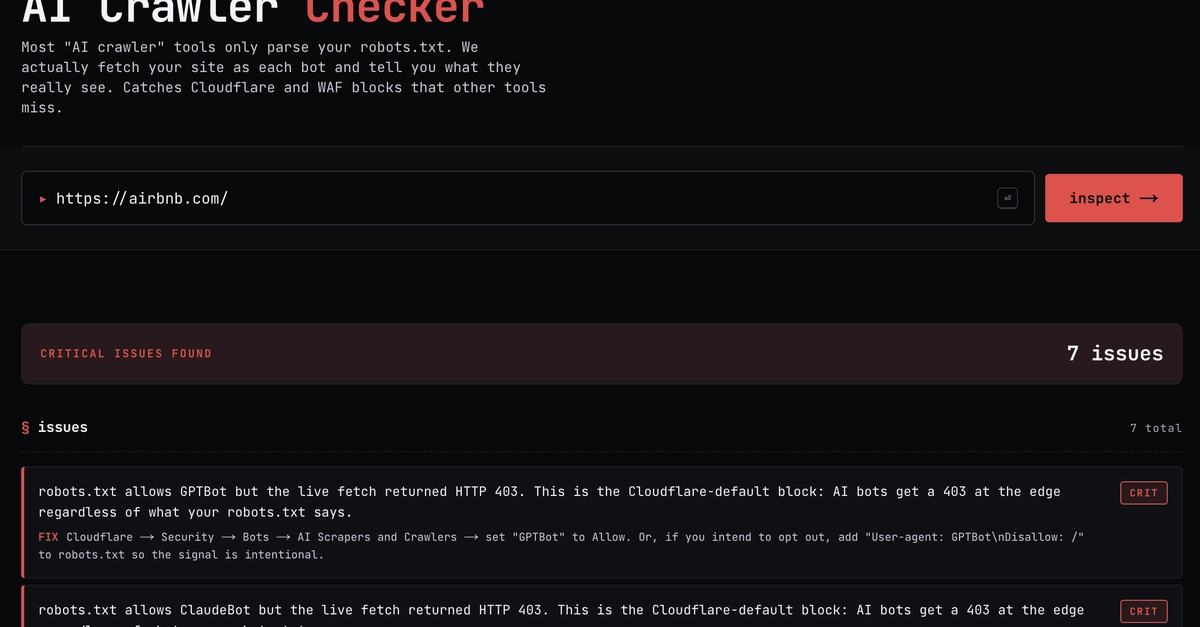
Your robots.txt lists User-agent: GPTBot - Allow: /. The page loads fine in a browser. The "AI crawler" checkers say you're configured correctly. But every time ChatGPT-User actually fetches your site, it gets a 403. You don't show up in ChatGPT when people ask about your product. You don't show up in Perplexity. The standard tools can't see why, because they're reading the wrong file.
This is the most common AI crawler accessibility failure in 2026, and almost nothing on the open web explains it correctly. Most write-ups stop at "here are five user-agents, add them to your robots.txt." That's table stakes. The actual blocks happen one layer up - at the CDN, at the WAF, in the JS shell of an SPA - and you can configure robots.txt perfectly while still being invisible to every model that matters.
The three ways your site gets blocked
Three layers. They fail for different reasons, they need different fixes, and from the outside they all look the same: your site, missing from ChatGPT, no obvious cause. Most write-ups treat them as one thing. That's how readers end up patching the wrong layer.
Layer 1: robots.txt disallow (application layer)