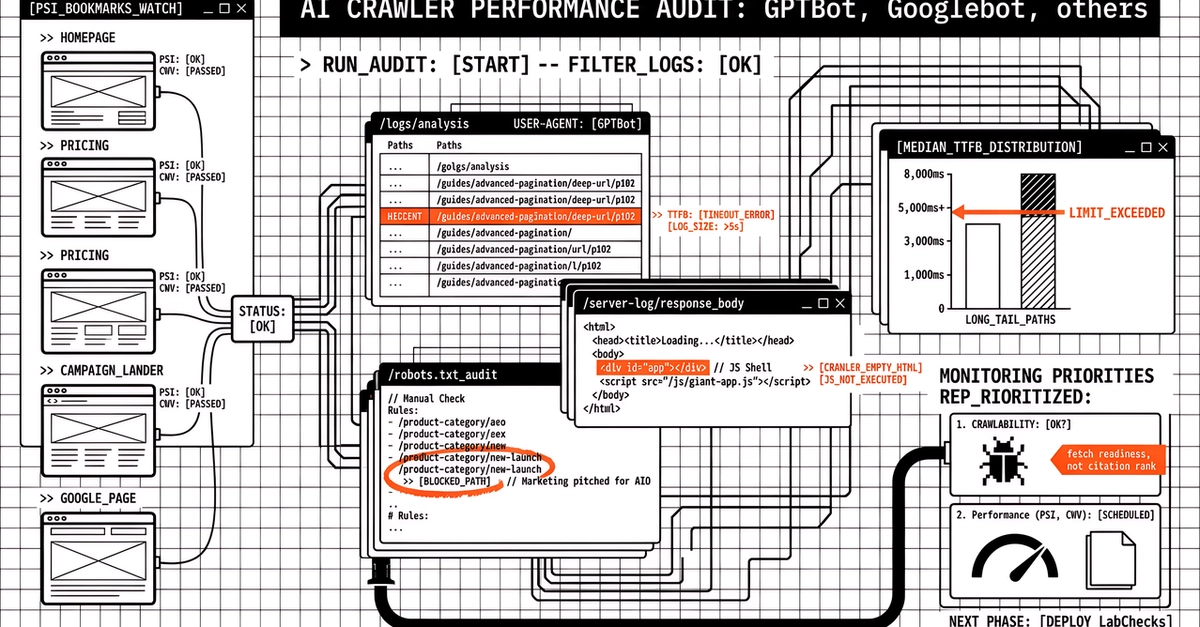
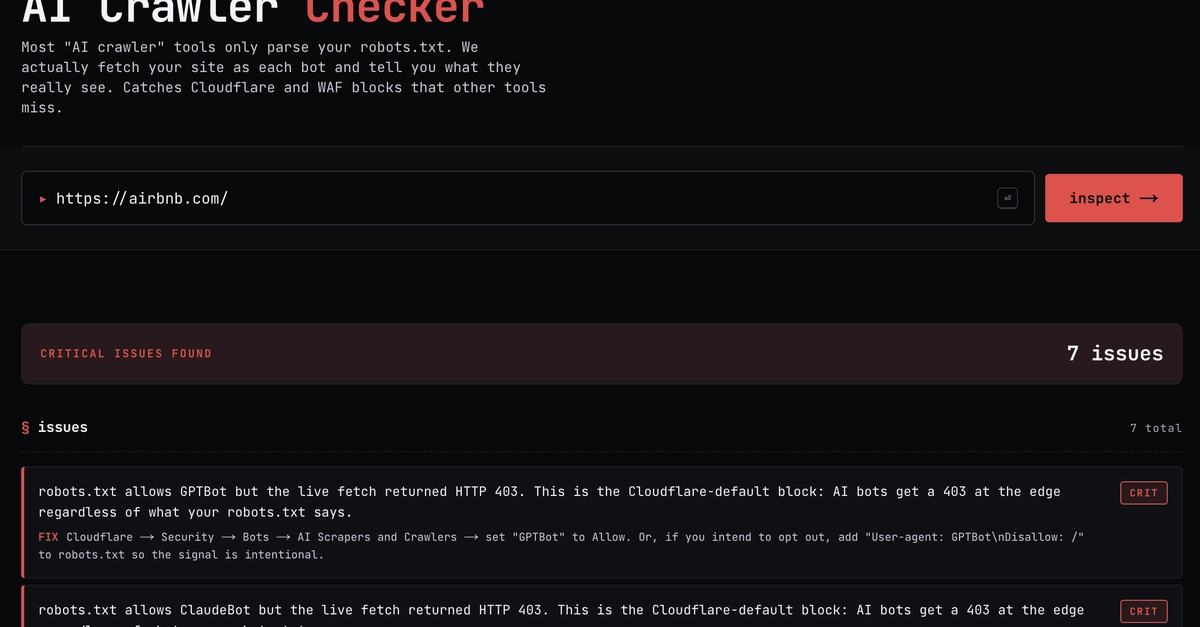
I was going through my server logs last month when I noticed something I'd been scrolling past for weeks. Buried in the bot traffic were names I vaguely recognised: GPTBot. ClaudeBot. meta-externalagent. PerplexityBot. Multiple visits daily, methodically working through different pages of my technical blog.
The reflex most developers have at this point including me, initially is to block them. There's an entire category of articles recommending exactly that: add a few directives to robots.txt, protect your content from being consumed by machines, done. I had the file open. I'd typed User-agent: GPTBot and had Disallow: / ready to go.
Then I stopped and asked a question I hadn't thought to ask: what actually happens after these bots finish reading? They don't discard the content. They use it. Every day, millions of people ask AI assistants technical questions, and those answers are built from content exactly like mine. The bots weren't extracting value from me. They were distributing me. The problem wasn't that they were reading my posts. The problem was that nobody knew the answers came from me.
Two Types of AI Crawlers. Only One Actually Helps You.
The label "AI crawler" covers very different things. There is a hard split between: