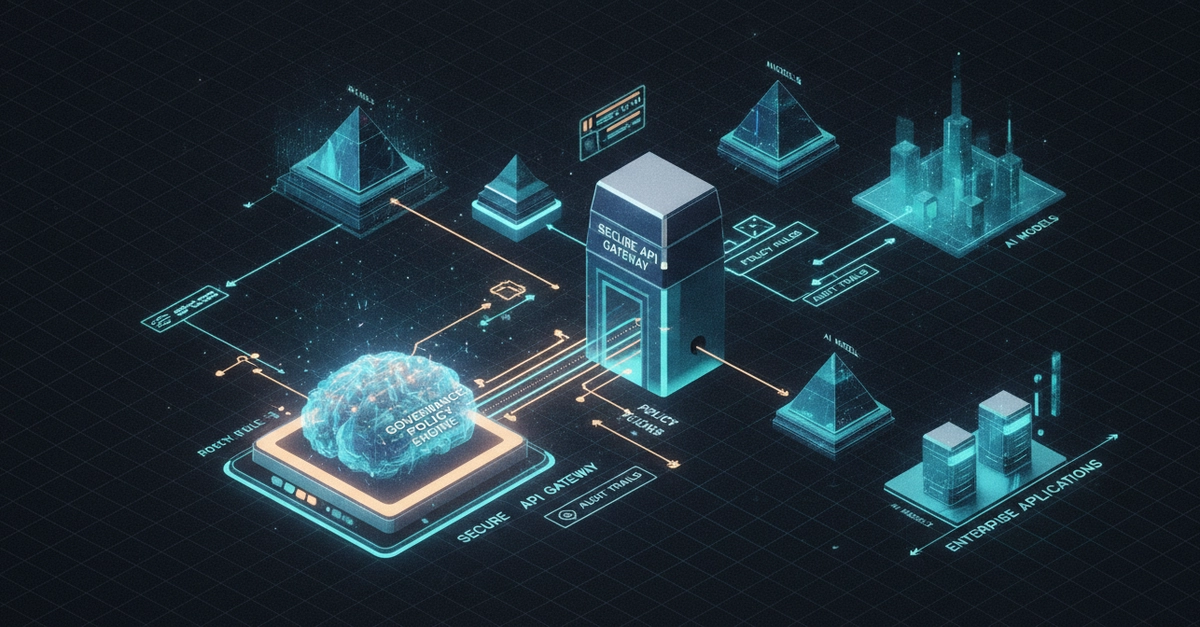
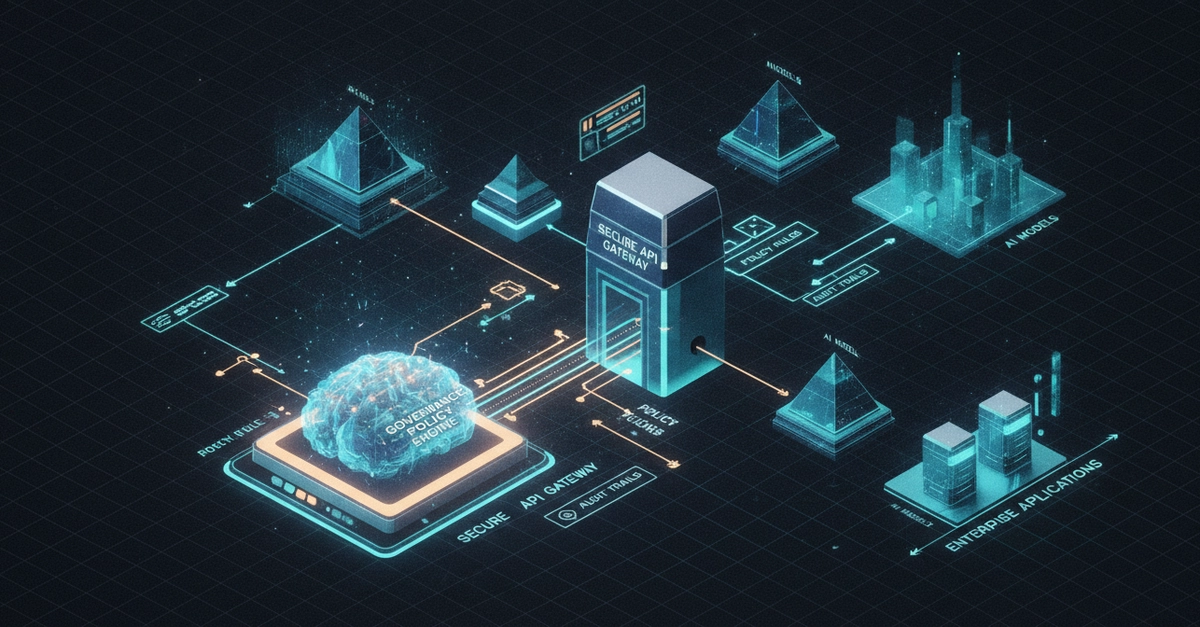
Every enterprise AI governance framework I've seen has the same structural flaw: it was written to prevent the last incident, not the next one.
There's a pattern in enterprise AI governance that I've observed often enough to call it a rule.
An organization deploys AI tools with minimal formal governance. Something goes wrong — a data exposure, a compliance finding, a public embarrassment, an internal incident where an AI agent did something nobody anticipated. The organization responds by writing a policy. The policy addresses exactly what happened. It says nothing about the seventeen related failure modes that share the same root cause.
Then something else goes wrong. Another policy gets written.
The resulting governance framework is a collection of reactive patches rather than a coherent risk architecture. It grows by incident, not by design. And because each policy addresses a specific past event rather than a category of future risk, the framework always has gaps — specifically, gaps around things that haven't happened yet.