I once spent nearly a week trying to fix a web scraper that, on paper, had absolutely no reason to fail. The target website wasn't using aggressive, visible defense walls. My script spaced out requests naturally, rotated common user agents, and used browser automation configured to mimic human interactions down to mouse movements.
Yet, the results were an absolute nightmare. Some batches of requests would go through cleanly, while others immediately triggered CAPTCHAs or returned 403 Forbidden errors. Every single time I thought I had patched the logic, the failure rate climbed right back up.
Like most developers, my default instinct was to assume the application layer was broken. I went down a rabbit hole optimization sprint checking request headers, browser fingerprints, cookies, and session persistence. Nothing explained the wild inconsistency until I noticed a strange clue: some proxy pools performed beautifully, while others crashed on the exact same codebase.
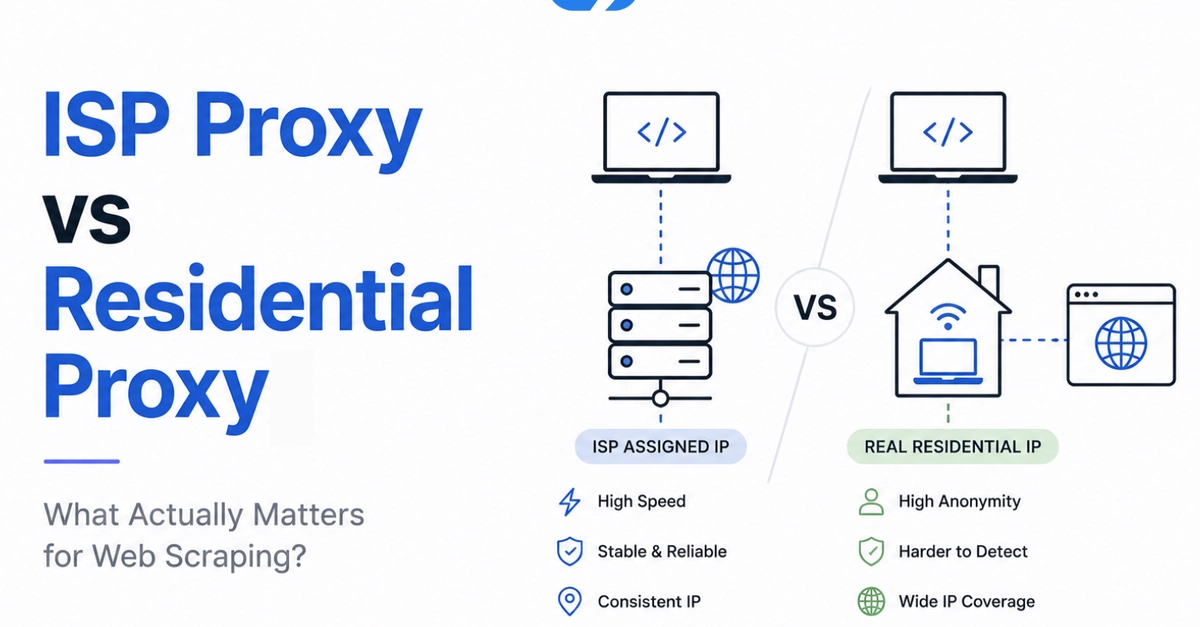
The code wasn’t the issue. The culprit was a fundamental misunderstanding of proxy network architecture.
Looking Beyond the IP Address: Enter the ASN