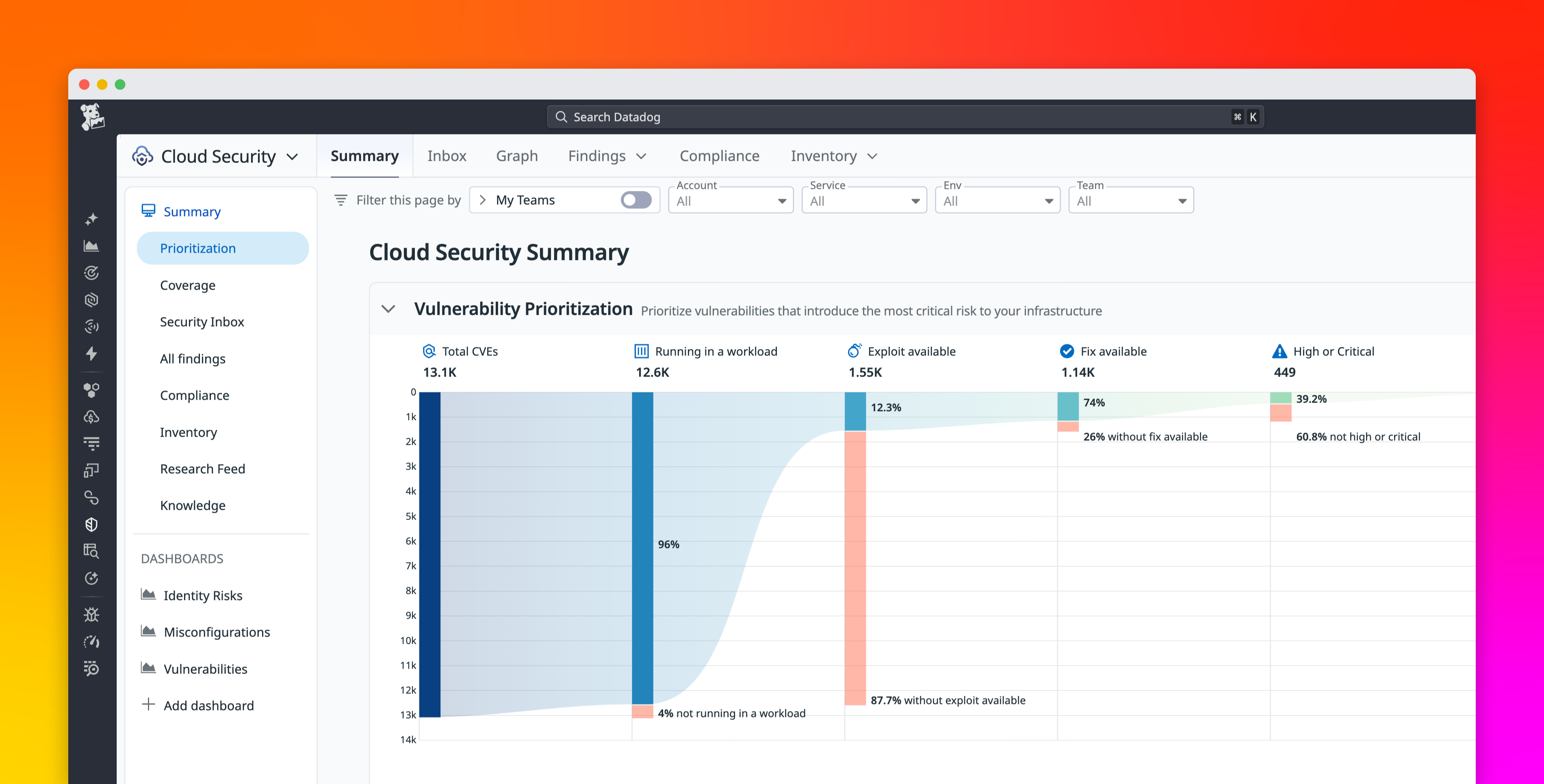
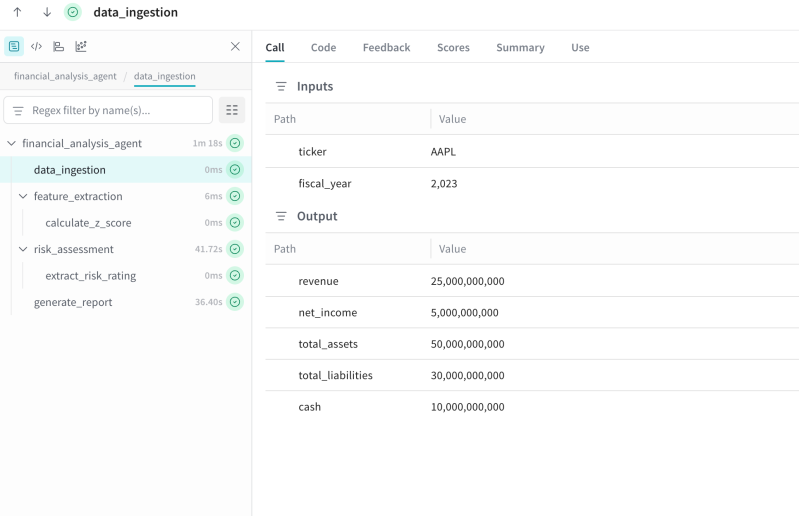
For years, observability helped engineering teams understand whether their systems were healthy.
If an API failed, logs showed it.
If latency increased, dashboards reflected it.
If CPU, memory, or disk usage crossed a limit, alerts helped teams respond quickly.
Traditional systems usually failed loudly.