Part 5 of a series on building reliable AI systems
So far in this series, we explored:
AI testing fundamentals
Evaluation pipelines
RAG evaluation
Part 5 of a series on building reliable AI systems So far in this series, we explored: AI...
Part 5 of a series on building reliable AI systems
So far in this series, we explored:
AI testing fundamentals
Evaluation pipelines
RAG evaluation

It’s a seemingly simple question, but there isn’t a satisfying answer today.

Your AI Model Is Deployed… Now What? Monitoring, Observability & Why AI...

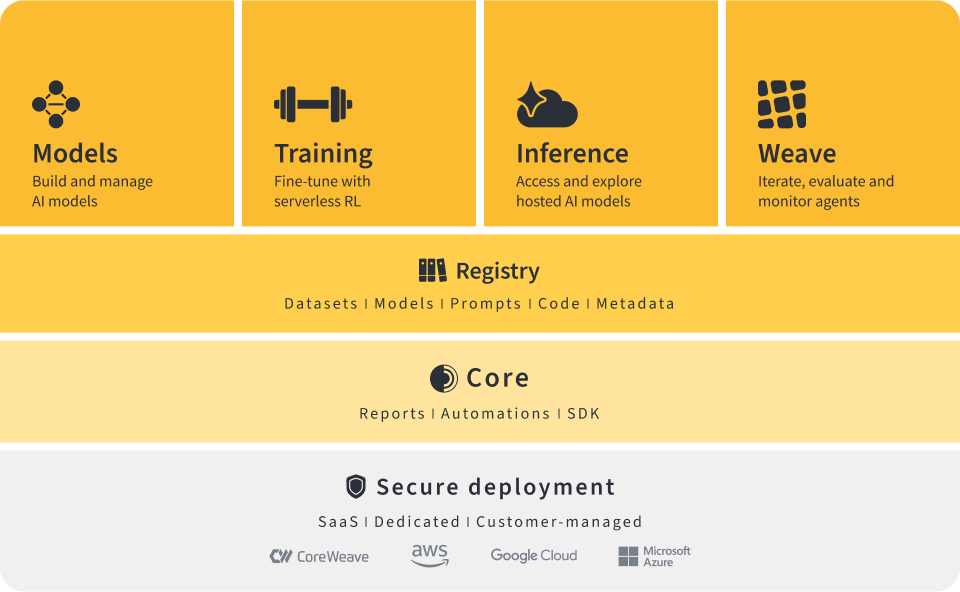
For years, observability helped engineering teams understand whether their systems were healthy. If...
Traditional observability was designed for deterministic software, focusing on infrastructure health through CPU usage, memory,…

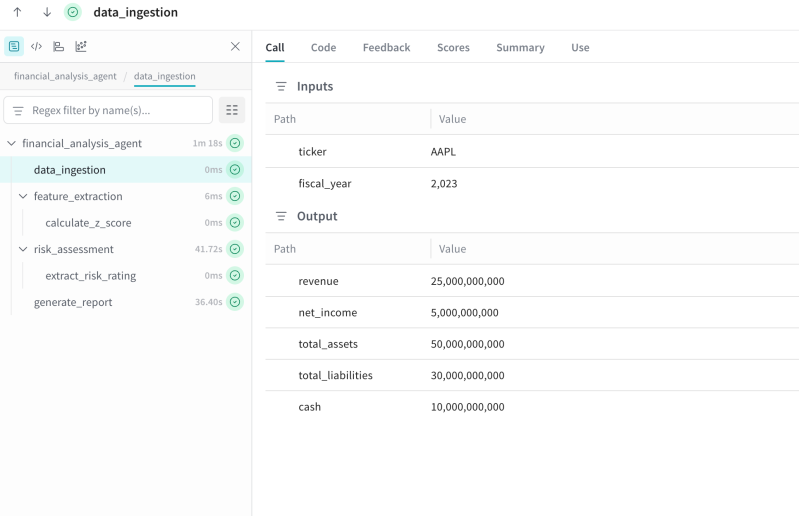
Multi-agent AI systems fail silently. Learn what proper observability looks like when agents orchestrate agents, and how Sentry…

Agents disappoint in production when we ask them to drive on roads built for dashboards. Build these four guarantees into the…