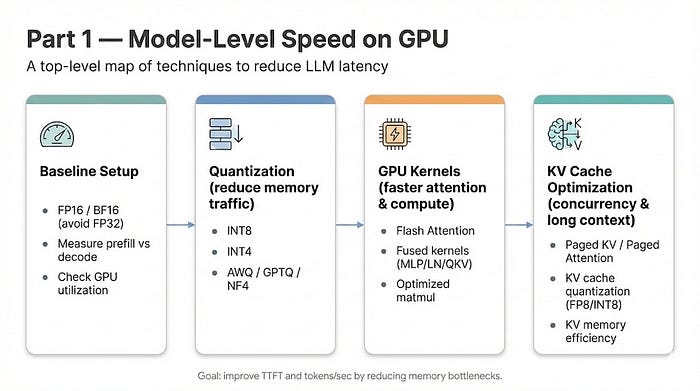
A field report from building a CPU-only, distributed LLM pipeline for large-scale scientific literature extraction. No GPUs. A lot of quantization. And four silent data-quality bugs that taught me more than the happy path ever did.
The constraint that started it all
Our team runs an internal research cluster: a couple dozen older x86 servers, plenty of RAM, zero GPUs. The mandate was to extract structured data — effect sizes, the entity each one describes, and the direction of effect — from ~10,000 full-text research papers, so a downstream meta-analysis could pool them.
The obvious 2024-era answer is "send it to a hosted LLM API." That wasn't on the table for data-governance reasons: the corpus had to stay on-prem. So the real question became:
Can you do serious LLM extraction at the 10k-document scale with CPUs only?