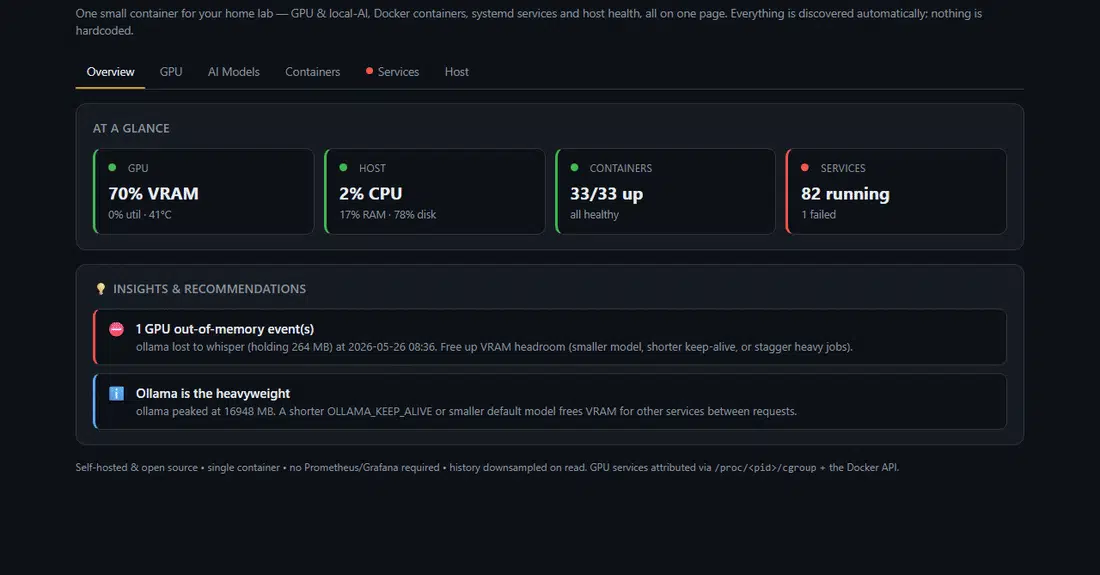
This is the technical, reproducible version of a fix I shipped on my own homelab. If you want the narrative version, that's on Medium. This one is the recipe: the measurements, the math, the Modelfile, and the exact prompt I gave Claude Code to generate it. Copy-paste friendly.
Repo for the dashboard used throughout: https://github.com/SikamikanikoBG/homelab-monitor
TL;DR
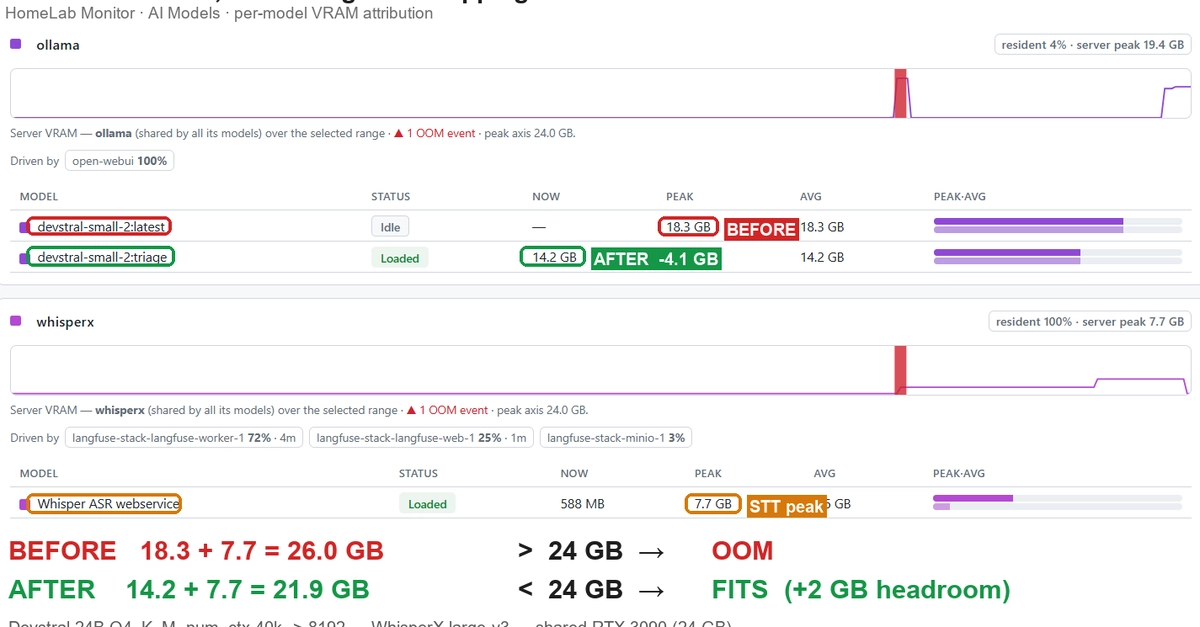
One 24GB RTX 3090, two GPU services: WhisperX large-v3 (STT, 7.7GB peak) and a Devstral Small 24B email-triage LLM (Q4_K_M, ~18.3GB).
18.3 + 7.7 = 26GB → CUDA OOM whenever they overlapped.