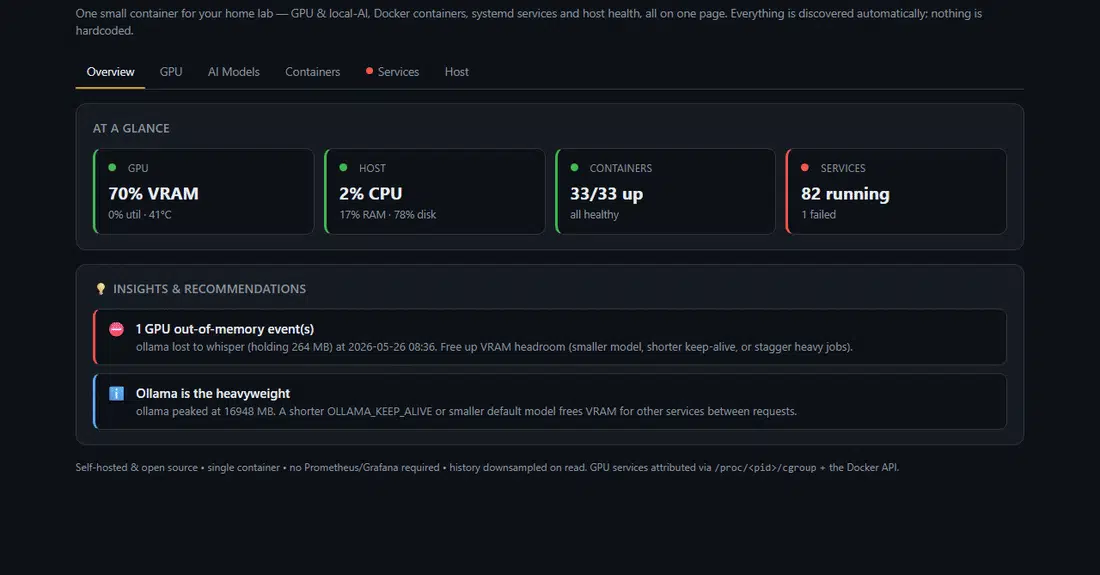
Quick story.
I run a small homelab — one box, an NVIDIA card, around ten Docker containers, and a couple of local model servers (Ollama mostly, vLLM when I'm playing around).
Every "why is this model OOM-ing" turned into the same five minutes of archaeology:
nvidia-smi → pick a PID
ps -o cgroup -p → find the container ID






