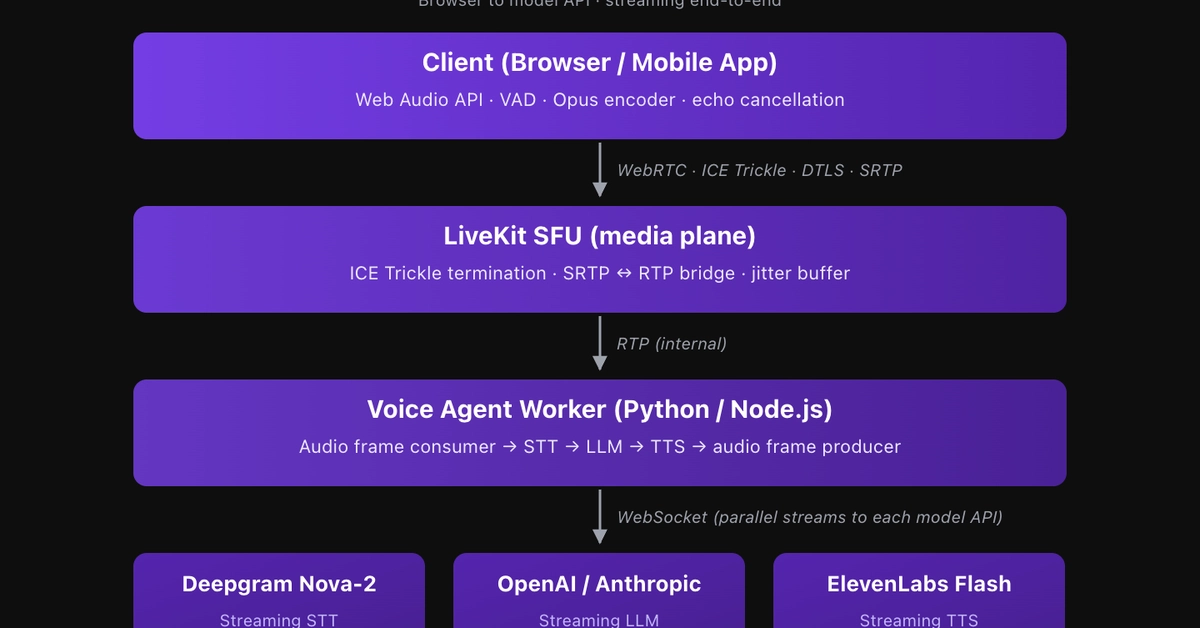
I recently built a production-grade real-time Voice AI workspace from scratch. While the whole system has many moving parts, two components required the most careful engineering: the authentication middleware between services and the Speech-to-Text (STT) pipeline.
Here’s exactly how I approached and solved both.
The Middleware Problem
I needed two local microservices — a WebRTC audio server and a FastMCP server — to communicate securely.
I didn’t want to introduce a database, Redis, or any hardcoded secrets. The solution had to be lightweight, stateless, and still reasonably secure for internal communication.