In my previous article, Bypassing the Multimodal Tax, I broke down how decoupling audio processing from cloud LLMs—using local STT and fast text inference—drastically cuts API costs and secures biometric privacy. We solved the cost and the scale.
But in conversational AI, there is a third, equally critical metric: Latency. If you have ever built a voice agent, you know exactly what I am talking about. It’s that painful 3 to 5-second "awkward silence" where the user has finished speaking, and the AI is silently crunching tokens in the background before uttering a single word. In a real-world conversation, a 3-second pause feels like an eternity. It shatters the illusion of human interaction.
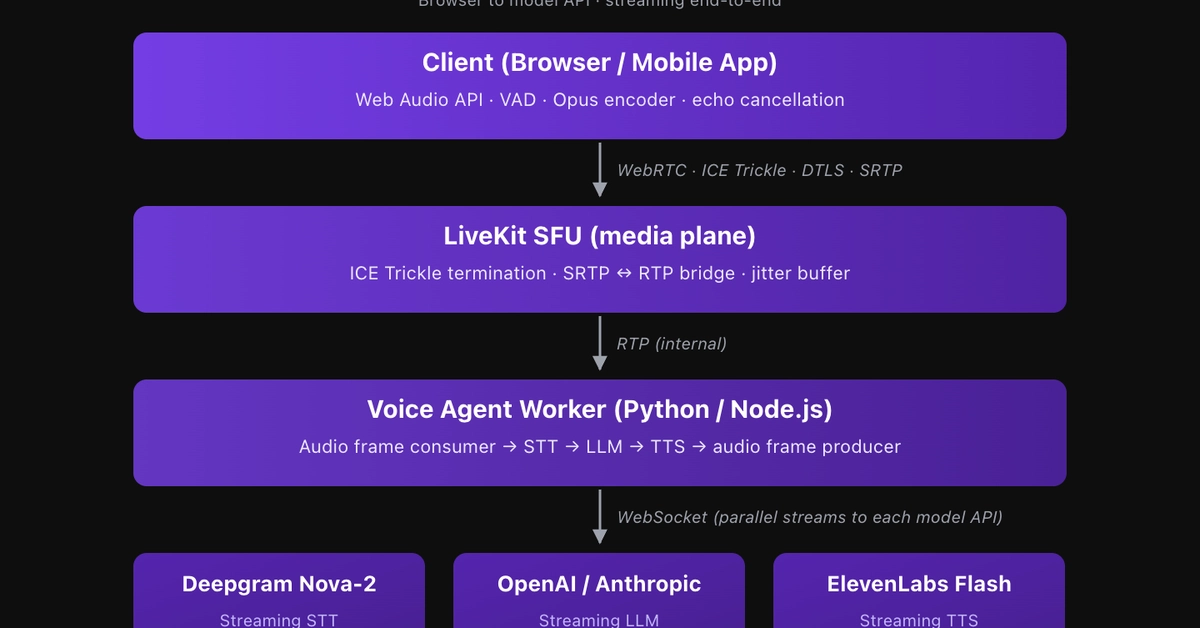
Here is a deep dive into the system architecture and the Python logic behind LangForge, explaining how I completely eliminated that awkward silence using a concurrent, multithreaded producer-consumer streaming pipeline.
The Naive Approach: The Blocking Pipeline (Synchronous)
Most tutorials and beginner projects handle voice AI sequentially. They treat the LLM generation and the Text-to-Speech (TTS) synthesis as isolated, blocking functions. The architecture looks like this: