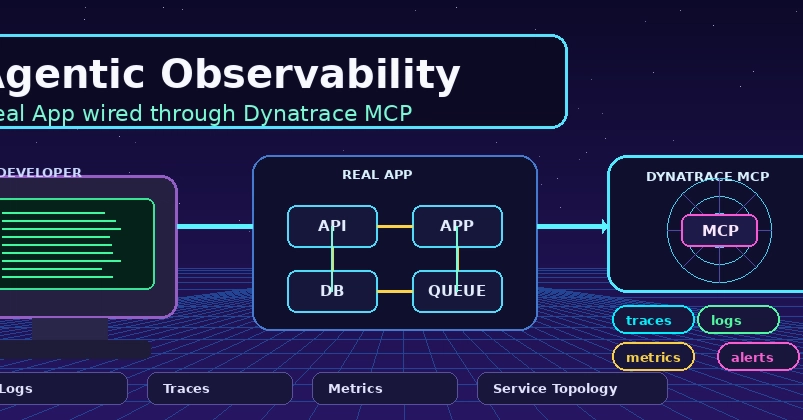
A backend service falls over at 2am and you know the drill: open the dashboard, follow the trace, find the bad deploy, roll back. Twenty years of tooling (logs, metrics, traces, APM) exists to answer "what just happened, and why?"
Now your robot bricks a grasp at 2am. What do you open?
There's no trace. The "request" was a 40-second episode of a policy reacting to the physical world. The failure isn't in a log line. It's in the half-second where the gripper closed early, which only makes sense if you can see the wrist camera, the joint torques, and the policy's action outputs on the same clock. You can't grep that. And the regression that caused it shipped because "it worked in sim" and nobody re-ran it against the 3,000 episodes where it used to work.
We have Datadog for services and Weights & Biases for training. We have almost nothing for the part in between: the run itself. That gap is where robotics observability lives, and it's about to matter a lot, because every team shipping VLA, imitation, and RL policies is hitting the same wall.
The unit of debugging is the episode, not the log line