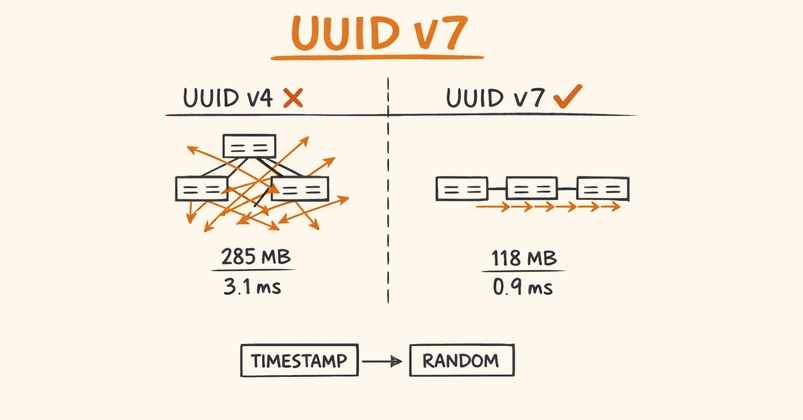
You add a UUID primary key to your PostgreSQL table. Everything works great in development. You get to a million rows in production and suddenly your INSERT latency spikes, VACUUM runs longer, and index size is two to three times what you expected. You didn't change anything. What happened?
The problem is UUID v4. Not the concept — the version. UUID v4 is purely random, and purely random identifiers are one of the worst choices you can make for a database primary key. The fix exists, it's been standardized, and almost nobody uses it yet: UUID v7.
I've dealt with this in vatnode.dev and pi-pi.ee — systems where identifier strategy matters because every row is indexed, queried, and sorted. Here's what I learned, and why UUID v7 is the right choice for most production systems in 2026.
What UUID Actually Is
UUID stands for Universally Unique Identifier. The format is always the same: 128 bits, represented as 32 hexadecimal characters split by hyphens into groups of 8-4-4-4-12:





