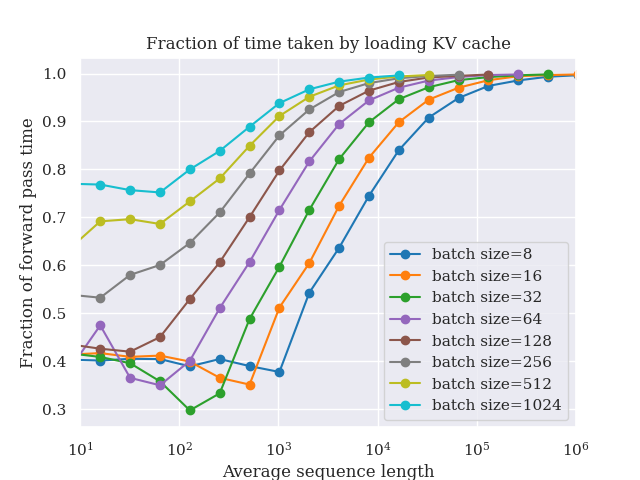
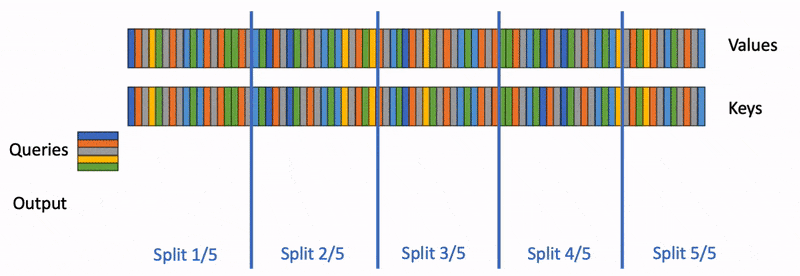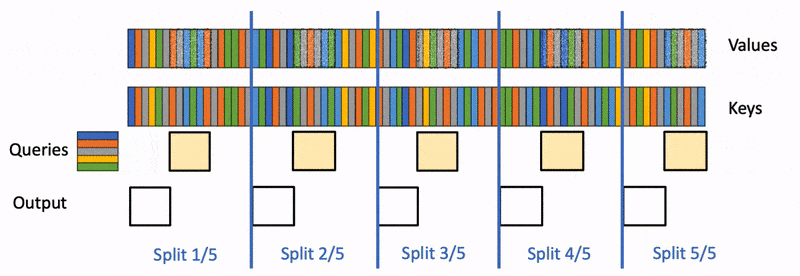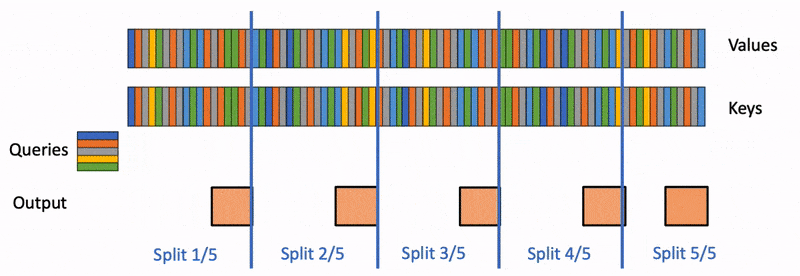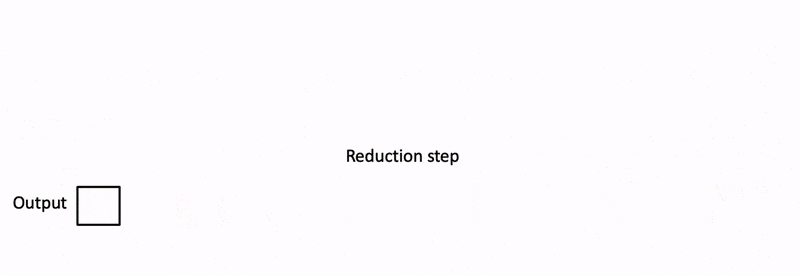
Speculative decoding cut LLM inference latency by predicting multiple tokens ahead and validating them with the base model. It works — but you pay for it with a separate draft model, a second KV cache, and acceptance rates that fall off when the drafter misreads the distribution. Orthrus is a research direction that aims for the same speedup without those overheads. It bolts a trainable diffusion attention module onto each layer of a frozen autoregressive Transformer and uses it to emit blocks of tokens in parallel.
The claim that should catch a developer's eye: 32 tokens per forward pass, while the base model's output distribution stays mathematically identical. If the math holds in practice, you get parallel generation without the "is the drafter agreeing with the target" hand-wringing that defines speculative decoding.
This is still early research, not a pip install. The architecture is worth understanding anyway, because it points at a different design space for self-hosted inference — one where the speedup comes from inside the model, not from a separate drafter running next to it.
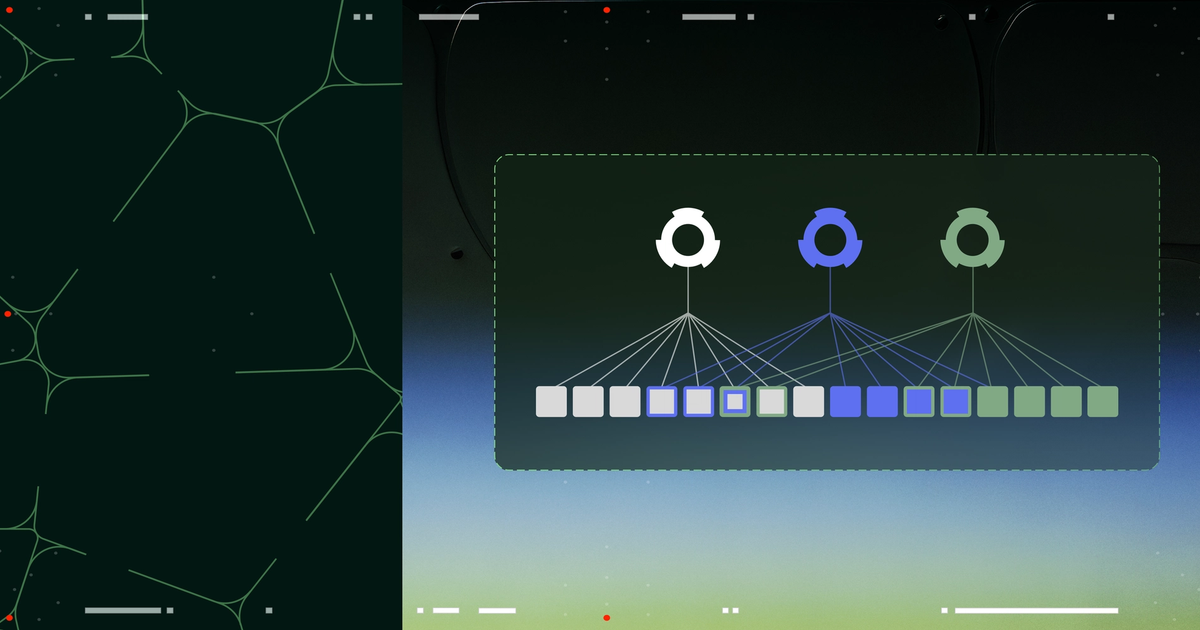
How Orthrus generates tokens in parallel
The base Transformer stays frozen. Orthrus inserts a diffusion attention module at each layer that operates on a set of placeholder positions — a block of 32 future tokens in the published configuration. During inference, the diffusion module iteratively refines those placeholders into concrete tokens through a small number of denoising steps that share the existing layer activations.