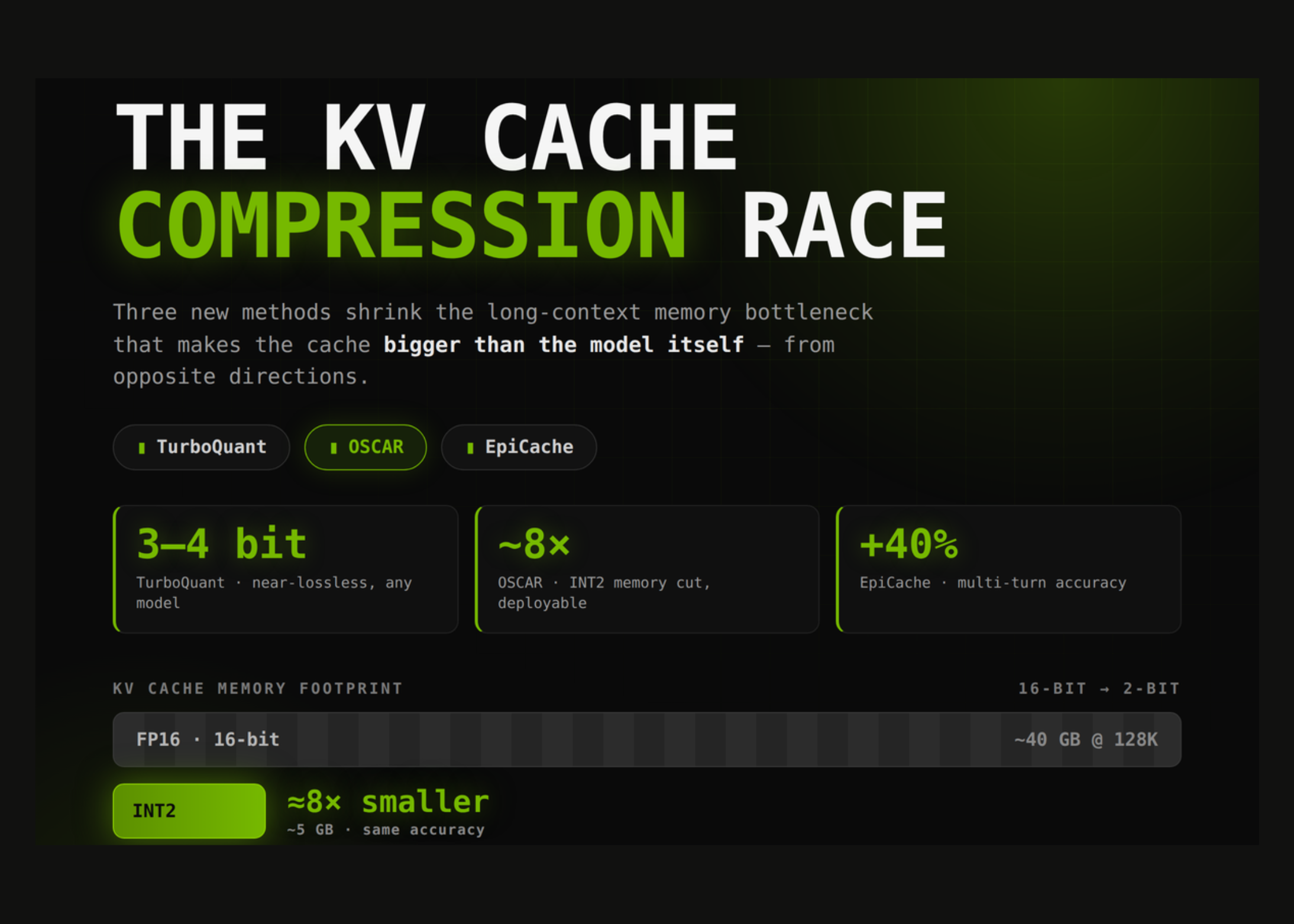
Tether AI just released TurboQuant as open-source software, delivering a tool that compresses the memory footprint of large language model inference by up to five times. The technology targets a specific bottleneck called the key-value (KV) cache, which is essentially the working memory that transformer models use to keep track of context during a conversation.
What TurboQuant actually does
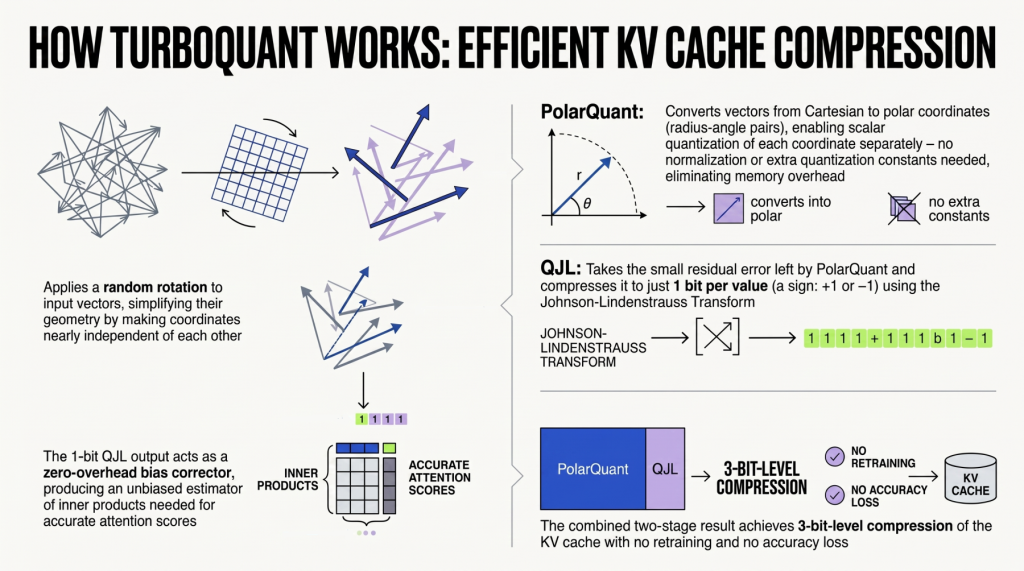
The algorithm behind TurboQuant originated from Google Research, which published the initial details on March 24, 2026. What Tether AI has done is take that research paper and turn it into something developers can actually deploy in production. Tether’s release includes a full quantization pipeline, framework adapters, and comprehensive documentation.
Quantization is a technique that reduces the precision of numbers used in neural network computations. Instead of storing values as 16-bit or 32-bit floating point numbers, you compress them down to 4-bit or even 2-bit representations. TurboQuant handles this for the KV cache specifically.
No model retraining or fine-tuning is required. Developers can apply TurboQuant to existing models and existing inference frameworks without starting from scratch.